《Velox: Meta’s Unified Execution Engine》笔记
文章目录
背景 现在业界中针对特定工作负载的计算引擎太多,导致计算引擎孤岛化。他们之间难以共享一些通用的优化手段。Velox就是为了解决这个问题而生的,它是一个开源的c++数据库加速库。Velox 提供了可重用、可扩展、高性能且方言无关的数据处理组件,用于构建执行引擎和增强数据管理系统。该库高度依赖向量化和自适应,从头开始设计以支持对复杂数据类型的高效计算,因为这些数据类型在现代工作负载中无处不在。目前,Velox 已集成或正在集成到 Meta 的十多个数据系统中,它在以下方面提供了好处:(a) 全面吸收了以前仅在个别引擎中发现的优化,提高了性能;(b)提高了数据用户的一致性;(c)通过促进可重用性提高了工程效率。
目标
运行效率:Velox 充分吸收了以前在各个引擎中实现的运行时优化(如充分利用 SIMD、Lazy Evaluation、自适应谓词重排和下推、公共子表达式消除、对编码数据的执行、代码生成等)。
语义一致性:通过相同的执行库,计算引擎在相同输入下可以返回一致的输出,保证了不同计算引擎之间的语义一致性。
工程效率:通过对Velox的集中维护,从而减少工程重复并促进可重用性。
Velox Use Case
presto: Prestissimo项目(https://github.com/prestodb/presto/tree/master/presto-native-execution),类似apache gluten, 将presto的计划片段offload到velox中去执行,从而获得性能收益。
spark: spruce项目,资料不多
实时处理:xstream–流处理,scribe–消息总线
机器学习:TorchArrow--数据预处理,F3--特征工程
高级组件实现
类型系统
包含标量,复杂类型,嵌套类型,包括struct, map, tensor(张量)等,用户可通过接口扩展自定义类型。
列
和和arrow兼容的列式布局,支持多种编码:flat/dict/const/rle/bias。
velox提出了lazy vectors的概念,lazy vector只有初次被访问时才会物化,减少物化代价。CH中已实现: https://github.com/ClickHouse/ClickHouse/pull/55518
velox提供了zero-copy的decoded vector抽象,提供了统一的访问api, 使得具体vector编码对用户透明
velox中string vector的设计如下,这样做的好处是
- string vector中每行长度相同,方便随机更行任意索引位置
- StringView中包含长度为4的前缀信息,方便对字符串进行快速筛选

velox中列的实现支持乱序写。首先原始类型都是定长的,本身就支持乱序写;其次string类型由于其特殊设计也是定长的;最后对于array或map等复杂类型的列实现,维护两个向量分别表示每一列的offset和length, 对array或map column的乱序写就是对内部的offset和length向量的乱序写。这样的设计除了支持乱序写之外,还支持向量切片,向量重排。
velox中支持了多种column encoding,跟CH类似,这里略过
表达式计算
velox表达式计算完全兼容列式格式,优化手段包括:公共子表达式消除,常量折叠,null值传播,encoding-ware evaluation
velox中表达式由节点组成,节点类型包括literal, function, cast, lambda, input, 大体上和CH相同。
velox中表达式的运行时优化有公共子表达式消除,常量折叠,自适应谓词重排。自适应谓词重排是将计算代价最小和区分度最大的谓词放在谓词列表的前面,目的是减少谓词计算代价。CH目前只有前两个优化。
velox表达式计算优化
- 如果表达式遵循空值传播规则(func(a,b)中任何参数为null, 输出为null), 且输入为null, 则跳过计算。CH中实现了类似特性:https://github.com/ClickHouse/ClickHouse/pull/73820
- 如果表达式是公共子表达式且已经标记为计算完成,则跳过计算
dict encoded column的peeling优化:将对字典编码向量的计算转化为对其低基数字典的计算
dict encoded column的cache优化:如果字典编码向量中的字典是全局的,即使输入包含多个batch, 在计算表达式时也只需要基于字典做一次计算形成一个全局的新字典,然后分别套上每个batch对应的index向量,生成新的dict encoded column
codegen: 不同于CH生成llvm ir, velox直接生成c++代码并编译,编译时间太长,还只是实验特性
函数
标量函数
velox中函数的实现框架提供了简单的逐行处理接口,方便用户二开,逐行处理时, velox保证循环内函数调用被inline, 提供了编译器自动向量化的可能。同时velox也支持向量化接口。语义上尽量兼容presto和spark,当然不可避免的有diff
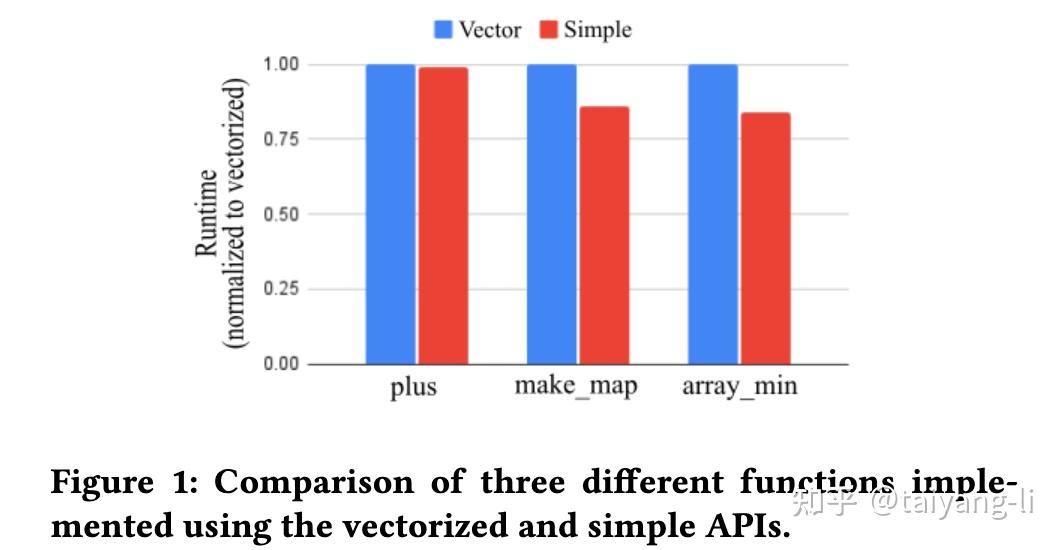
从下图可以看到,逐行处理实现的性能有时候会超过向量实现
velox针对字符串函数有特殊优化,当输入只包含ascii字符时,按照ascii对应的实现执行,以提升性能,CH中实现了类似特性:https://github.com/ClickHouse/ClickHouse/pull/61632。由于velox对string column的特殊设计,string function的输出列可直接引用输入列中的buffer切片,避免了大量内存分配。
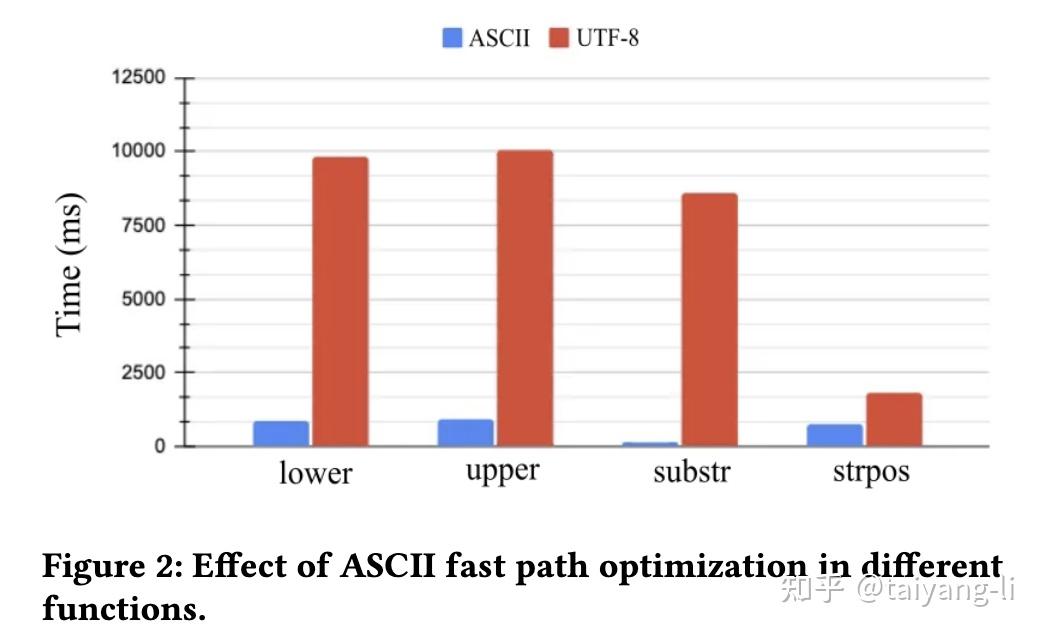
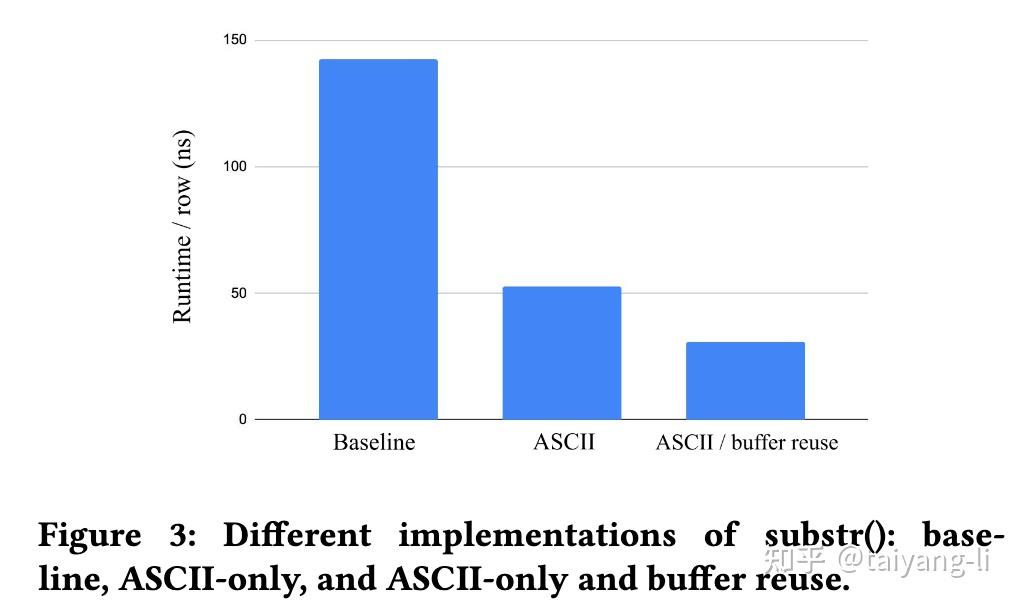
聚合函数
velox聚合函数的实现中有两个优化。目前在CH中都已实现
第一个优化是单一聚合优化,当没有group by 任何key时,无需创建hash table, 直接对中间状态进行更新,避免了hash table相关开销。
第二个优化是关于hash table中间状态存储的,如果中间状态是定长的,则直接将其存储于hash table中,否则将其分配于buffer中,hash table中存储指向buffer对应位置的指针
算子
包含tablescan, project, filter, aggregate, exchange/merge, orderby, hashjoin, mergejoin, unnest等。
这里介绍了pipeline概念,pipeline的起点是source/exchange, 终点是exchange/sink。
velox支持用户自定义算子,例如自定义支持流式计算的聚合算子。
tablescan的优化,过滤下推和延迟物化。
filter的优化
- 谓词重排
- in表达式优化(这里没看懂?,原文:Velox also provides an efficient implementation for large IN filters, used for hash join pushdown, which allows it to trigger 4 cache misses at a time.)
- filter和project结合成filterproject, 在其实现中,filter expr和project expr在同一个DAG中,对输入数据,首先计算filter expr结果,然后以其作为掩码计算project expr。velox能这么优化也是得益于其向量设计。
aggregate和join的优化:核心在于hash table.
- 当所有group by key只映射到很小的整数域,直接将hash table转化为array
- join build端根据key生成bloom filter, 对join probe端底层的scan使用这个
IO
支持不同编码(orc/parquet), 支持不同文件系统(local/hdfs/s3)。这个都差不多
序列化器
支持PrestoPage格式,支持Spark的UnsafeRow格式
资源管理
包含内存池,Cache, pipeline执行,线程池,spill等
spill支持:内存紧张时spill, 内存宽裕时恢复执行。CH中join/sort/aggregate都支持spill功能。
本地缓存:通过将远程io stall隐藏在cpu计算中,来提升查询性能。这里有个小优化,如果io range之间距离比较近,则合并读取,以减少远程io请求次数。CH有类似实现(https://github.com/ClickHouse/ClickHouse/pull/70534)。
性能测试
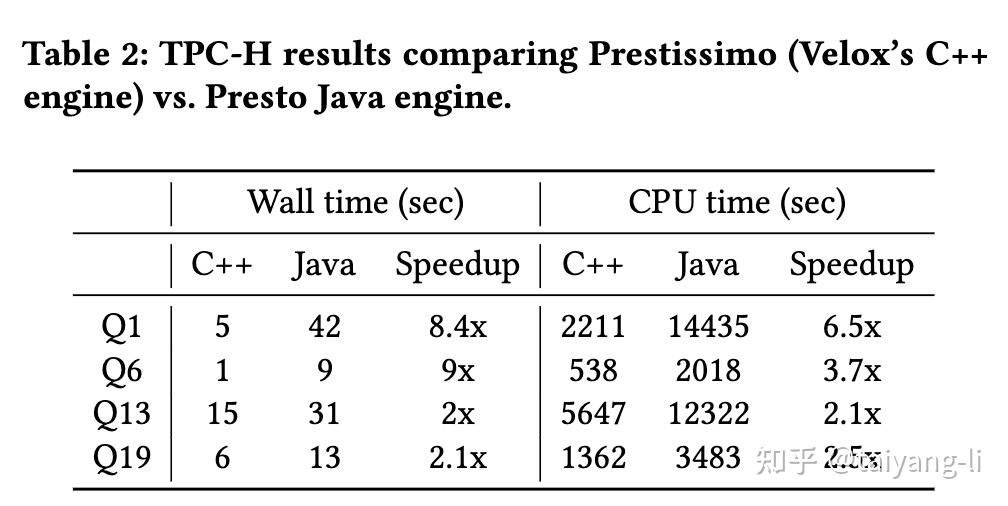
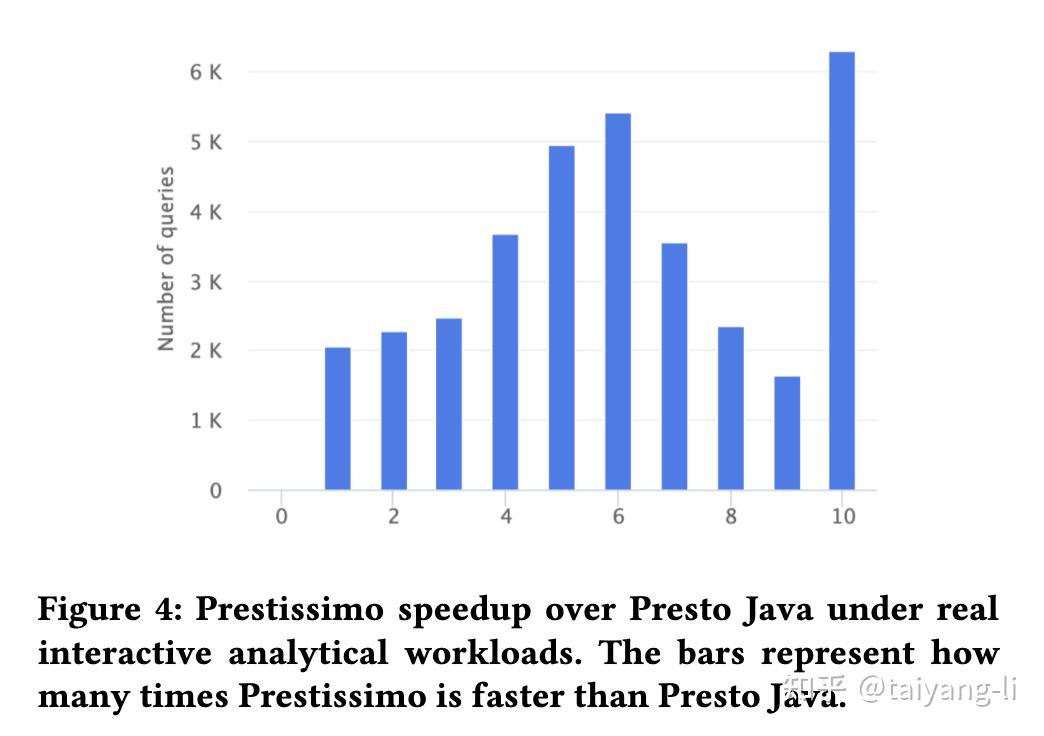
主要比较prestissimo(底层适用velox执行计算)和presto.
TPC-H数据集
Q1和Q6是cpu bound查询,所以prestissimo的加速效果更好。Q13和Q19的瓶颈在shuffle, 因此效果有限。
生产数据集
文章作者 后端侠
上次更新 2025-05-20