《The Composable Data Management System Manifesto》笔记
文章目录
介绍
虽然现代数据库系统表面上看起来可能不同,但是在内核中, 他们由一组类似的逻辑组件组成
- 语言前端:将用户输入转化成内部格式
- 中间表示(IR): 通常对应逻辑计划和物理计划
- 查询优化器:将IR转化为更有效的IR以便执行
- 执行引擎:在本地执行查询片段
- 执行运行时:为执行引擎提供运行环境
不同数据库中实现这些组件的数据结构算法也大致相同。然而不同数据库实现导致了碎片化和系统间重用性缺乏
论文作者来自Meta,他们提出将数据库分解成更模块化的可重用组件,简化新引擎的开发,同时降低维护成本,提供更一致的用户体验。整体技术栈如下所示
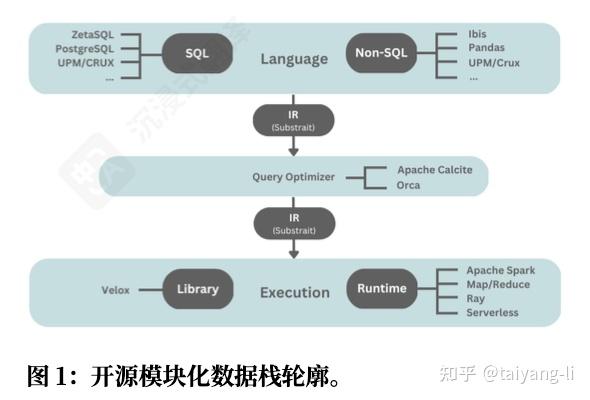
语言前端
一般的实现方式:通过C/C++ Parser和Analyzer,将SQL转化为IR, 通常基于Flex, Bison或Antlr实现。
带来的挑战:
- 非SQL如dataframe api导致了语言景观的碎片化。
- 不同的SQL方便,如Hive, ClickHouse, Presto
spark的解决方案:进行扩展,让SQL和非SQL生成相同的IR。更普遍的,语言通过统一的IR和执行相连接。
中间表示 IR
尽管数据库内核中IR和内部紧密耦合,但他们只是相同数据处理原语的不同表示。他们都表示Expression DAG, filter, projection, sort, join, aggregate, window, repartition等代数计算,除此之外变化很小。
Substrait提供了统一的跨语言IR规范,旨在创建一种通用语言来描述计算。Substrait使得语言和执行可以完全解耦和组件化。但也带来了以下挑战:
任何IR更待都需要向后兼容。
当前IR描述性不够强,无法确保相同语义
未定义行为:抛异常 or 忽略?
数组索引:0-based or 1-based ?
不同系统中函数集不同,同名函数的语义也不尽相同
论文指出未来的道路是通过语言和执行统一来绕过方言和函数包的不兼容性。
查询优化
Orca和Apache Calcite是著名的可组合和可重用优化器。
Orca 通过使用基于 XML 的语 言在优化器和执行引擎之间交换信息,提供了优化器和执行 引擎之间的清晰分离。虽然 Orca 旨在模块化和可扩展,但据 报道,将其与非 PostgreSQL 系统集成并不简单
Apache Calcite 已成功集成到多个开源项目中,如 Apache Hive 和 Apache Phoenix,流处理引擎如 Apache Flink 和 Apache Samza,以及商业系统如 Qubole。但是Apache Calcite用 Java 编写的,使得将其嵌入 到对高效短运行查询支持重要的非 Java 系统中具有挑战性。
执行引擎
执行引擎负责接受查询片段(使用IR表示)作为输入,并利用执行运行时提供的本地资源执行。 特定查询片段的执行通常从表或索引Scan或Exchange作为输入开始,在处理传入数据后,以另一个Exchange或Sink结束。 常见的数据处理原语包括表达式评估、过滤、排序、连接、 解包以及其他实现 SQL 语义所需的运算符。
Velox [18] 是旨在填补这一空白的一个项目。Velox 是 第一个旨在为数据管理系统提供统一执行引擎的大型开源项 目。它提供了可重用、可扩展和方言无关的数据处理组件, 目前已被集成到 Meta 和其他十几个数据管理系统,包括 Presto 和 Spark 等分析查询引擎、流处理平台、数据仓库摄取基础设施、数据预处理和特征工程机器学习系统等。Velox 证明了不仅可以将执行组件化,还可以在整个堆栈中统一它。
执行运行时
执行运行时为执行引擎提供执行计算所需的环境。它负责
- 资源的调度和分配
- 任务之间的容器化和 适当的隔离(由于并行执行和多租户)。
- 分布式计算模型和节点间通信(例如,队列)。
尽管与任务隔离和任务间通信相关的标准化尚未出现,但通常有 两种设计选择:(a) 任务要么是隔离的(使用 cgroups 或其 他类型的容器)或者允许共享相同的进程空间,(b) 虚拟机要 么基于流,要么持久化到本地或远程文件系统。运行时是否能够收敛并提供更多可配置的数据管理模式是一个悬而未决的问题。但论文提出运行时不应该和数据库实现耦合。
Call For Action
尽管听起来有些理想 化,但仅通过利用 Ibis (语言)、 Substrait ( IR )、 Calcite (优化器)、 Velox (执行)和 Spark 、Ray 或Serverless架构,就可以构建一个功能相当齐全的技术栈。
题外话:Velox 对其列式布局进行了专门化,以允许更有效地操作字符串和复杂类型,以及更灵活的编码类型,后来与 Arrow 社区 合作扩展了列式标准( API )。扩展阅读https://lists.apache.org/thread/49qzofswg1r5z7zh39pjvd1m2ggz2kdq
结论
现状:数据库系统之间的重用程度非常有限,这导致了工作重复、高昂维护成本、创新速度放缓。
愿景:作者倡导对这些系统的设计和开发进行范式转变。通过组件化数据管理系统,可以加快创新的速度。我们相信可组合性是数据管理的未来,并希望更多的 人和组织能加入我们的这一努力
文章作者 后端侠
上次更新 2025-05-20