Gluten + CH backend性能优化--方法论
文章目录
Gluten + CH backend性能优化方法论
上篇我们介绍Gluten + CH backend性能开发中常用的工具链。本篇我们将展开讲讲Gluten + CH backend性能优化的思路和方法论。
在进行性能优化的过程中,首先要做的就是找到性能有问题的case,如哪个sql执行的比较慢;然后定性的识别系统的短板到底在哪块,在spark任务的哪个阶段,哪个算子?在识别出性能短板后,接下来要定量分析具体的性能瓶颈,到底是哪个函数慢了,哪个循环慢了?最后在定量分析的基础上使用一定的技巧进行性能优化。优化完成后还要将改进版本和基线版本进行比较,评估优化效果,如果效果没有达到预期,还要回到前面重新发现性能问题,直到达到预期效果为止。
flowchart TD
A[发现性能问题] --> B[识别系统短板]
B --> C[分析性能瓶颈]
C --> D[优化系统性能]
D --> E[评估优化效果]
E -- 效果未达预期 --> A
E -- 效果达预期 --> F[优化闭环完成]
发现性能问题
首先要强调下性能优化的时机:有句话说的好,过早优化是万恶之源。只有当系统的功能完备之后,才有条件讨论性能优化。在错误的功能上进行性能优化是没有意义的。
其次什么样的问题才算性能问题呢?这个问题很宽泛,让我们把视角聚焦到执行Gluten + CH backend的Spark任务上。我们在生产环境灰度Gluten时,会比较Gluten和Vanilla Spark在执行相同任务时的性能差异。发生以下情况时,我们会认为是Gluten性能问题:
- Gluten执行的耗时和Vanilla Spark基本持平,或慢于Vanilla Spark。这说明Native Engine的向量化执行优势没有体现出来,系统中必然存在某些短板影响了整体性能。
- Gluten执行的任务发生了OOM(out of memory)而Vanilla Spark正常。这说明Gluten执行时有executor进程的内存占用超过上限,需要优化其内存占用。优化内存占用也是性能优化的一个重要部分,但是它更多的和算子的spill实现相关,在这里我们不展开讨论。
当然除了从生产环境中发现性能问题外,我们还可通过各种Benchmark工具来发现性能问题。例如CH提交性能优化相关PR时,会自动触发流水线中的性能测试,它会比较master版本和当前PR版本的性能差异,从而快速确认PR是否引入了新的性能问题。
找到执行时间较长的Spark任务后,我们需要进一步识别系统短板,分析性能瓶颈,优化系统性能。
识别系统短板
当我们确定了哪个Spark任务有性能问题之后,接下来要做的就是该任务进行定性分析,找到性能短板,即它的性能卡在什么地方,哪个Stage,哪个任务,哪个算子?bound在哪些操作,是计算还是IO?
我们可以使用Spark Web UI来帮助我们查看不同层级 SQL -> Plan -> Stage -> Task -> Operator的全局执行情况,也可通过Spark日志深入到每个具体Task中,查看Native Engine的计算逻辑和性能指标。
分析性能瓶颈
当我们确定了Spark任务大概瓶颈在哪块时,接下来分两步:
- 第一步,根据生产环境的Case,构造能体现其性能短板的简化Case,在开发环境中复现,这样做的理由有:
- 生产环境数据量太大,执行一个任务可能需要数个小时,不适合后续的定量分析
- 生产环境的负载不稳定,干扰因素太多,可能会影响性能分析的准确性
- 生产环境一般是分布式集群,性能调优的工具链不一定完善
注意, 构造开发环境的Case时,应当尽量放大性能短板所在的部分,而适当简化其他部分。例如,如果一个Spark SQL的性能短板在某个Subquery上,那么我们可将该Subquery提取出来,构造一个独立的SQL来复现性能问题;同样的,如果性能短板在某个算子上,我们也可以将该算子提取出来,而简化其他算子。这样做的好处是减少了不必要的干扰因素,方便后续的定量分析。构造简化Case并不是一蹴而就的,可能要经过反复试错。
- 第二步,我们在开发环境中运行简化Case, 并使用性能调优工具进行定量分析,生成火焰图,找到代码级或指令级的性能瓶颈。这里推荐使用Intel Vtune进行分析,因为它的功能比较完善且使用相对简单,能查看火焰图、源代码、汇编代码,能进行热点分析、CPU微架构分析、内存访问分析和内存消费分析。
优化系统性能
到了这一步,我们不管在系统的宏观还是微观视角,都已经有了比较清晰的性能瓶颈定位。接下来就是要使用一定的技巧进行性能优化。
在Gluten+CH backend性能优化–问题与挑战篇中,我们已经介绍了Gluten + CH backend性能优化的常见问题和挑战。接下来我们将展开讲讲如何针对这些问题进行性能优化。
计划优化
在前面我们提到了Gluten + CH backend的计划优化面临的问题与挑战:由于各种各样的原因,最终Native Engine执行的物理计划并不是最优的。为了解决这个问题,我们在Spark和Gluten通用优化规则的基础上,增加了针对CH backend的优化规则,尽量使Native Engine执行的物理计划更优。
优化规则大致可分为两种, 一种是作用于逻辑计划,一种作用于物理计划,实际应用中两者是相辅相成的。
Spark AQE(Adaptive Query Execution)是Spark SQL中的优化技术,利用运行时的统计信息来选择最高效的查询执行计划,如通过合并减少shuffle分区数量,将sort-merge join转化为broadcast join,优化数据倾斜等等。Spark AQE提供了运行时的统计信息,如算子输出行数,可用于Gluten中的join reorder优化,或根据统计信息选择合适的CH join算法实现。
通过优化执行计划可以减少不必要的计算和数据传输,对提升Spark任务性能起到了事半功倍的效果。因此在优化Spark任务时,应当首先考虑是否有计划优化的空间。
IO优化
在Spark中,涉及到IO的操作主要是Scan、Shuffle和Insert算子。对于Shuffle算子,我们使用Apache Celeborn作为RSS(Remote Shuffle Service)来实现列式Shuffle,可参考Gluten + Celeborn: 让Native Spark 拥抱Cloud Native。对于Insert算子,我们和社区分别实现了ORC/Parquet(https://github.com/apache/incubator-gluten/pull/1595)表的列式写入功能,其IO性能是Vanilla的两倍。因此这里我们不展开讨论Shuffle和Insert算子的优化,而把视角聚焦到占比更大Scan算子上。
优化Scan算子时,我们可以从以下几个方面入手:
降低IO请求次数和请求量
因此Scan算子中,会频繁对远程IO进行请求,导致网络带宽和远程存储的压力过大。我们可以通过以下方式来减少IO请求次数和请求量:
- 列裁剪:只读取需要的列数据,避免读取不必要的数据。可以通过Column Pruning来实现。注意只有ORC、Parquet这种列式存储格式支持列裁剪。那么什么是列裁剪呢?列裁剪是指在读取数据时,只读取查询中需要的列,而不是读取整个表的所有列。这样可以减少IO请求量,提高性能。列式存储格式之所以能支持列裁剪,是因为它将数据按列存储,而不是按行存储。例如,文件中包含a, b, c, d四列数据,但是查询只需要a和c两列数据,那么列裁剪就只会读取a和c两列数据,而跳过b和d两列数据。
- 行裁剪:只读取需要的行数据,避免读取不必要的数据。可以通过Predicate Pushdown来实现。同样只对ORC、Parquet的列式存储格式有效。行裁剪是指在读取数据时,只读取满足查询条件的行,而不是读取整个文件的所有行,同样可以减少IO请求量,提高性能。那么行裁剪是如何实现的呢?对于最新版本的Parquet格式,它的文件级别、rowgroup级别和page级别都定义了minmax index(page级别可选)和bloom filter(可选),某列的minmax index是指该列在对应层级所有数据中的最大值、最小值、Null Count等信息,minmax index可用于快速过滤不满足范围查询的行,而Bloom Filter用于快速过滤不满足点查条件的概率数据结构。对于ORC格式,它的文件级别、stripe级别和rowgroup级别都定义了minmax index和bloom filter,原理类似。
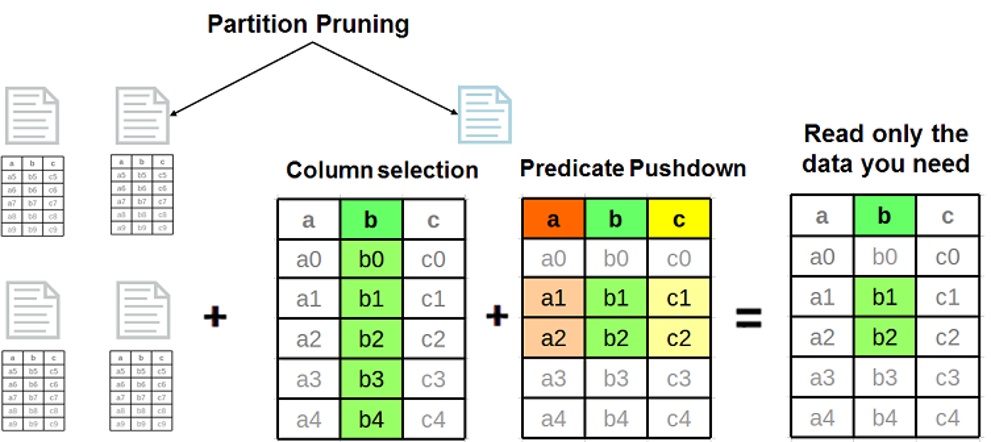
- 编码优化:使用更高效的编码方式来减少数据量。例如,ORC和Parquet格式都支持多种编码方式,如Run Length Encoding(RLE)、Dictionary Encoding等,这些编码方式结合默认的压缩算法可以有效减少列式数据的字节数,从而减少IO请求量,提升Scan算子性能。
我们可以看到,上面三种优化方式,列裁剪、行裁剪、编码优化,都是利用列式存储的优秀设计来尽可能减少查询的IO请求次数和请求量,他们的核心思想是尽量不读取不需要的数据。这也从侧面说明了ORC和Parquet相比Text、JSON格式在性能上的优越性。因此生产环境中应当尽量使用ORC或Parquet作为Hive表的存储格式。
异步IO模型
在Gluten的早期实现中,无论是Text、ORC还是Parquet文件,都是使用libhdfs3库的同步IO模型进行读取的。同步IO模型会阻塞工作线程,导致CPU空闲,无法充分利用CPU资源。为了提高Scan算子运行时的CPU利用率,我们可以使用异步IO模型来替代同步IO模型,在CPU计算时通过后台线程异步读取下一次的数据块,从而将IO延迟隐藏在CPU计算中。
但是不同格式下,由于文件的存储结构不同,CH中native reader读取模式不同,异步IO模型的实现也有所不同:
- ORC/Parquet: ORC/Parquet的读取模式是多次小范围随机读。ORC文件由多个Stripe组成,Parquet文件由d多个Row Group组成。当CPU在处理当前ORC Stripe或Parquet RowGroup时,可以通过异步IO模型来读取下一个ORC Stripe或Parquet RowGroup的数据。等到处理下个ORC Stripe或Parquet RowGroup时,数据已经准备好了,可以直接使用。注意由于上面的列裁剪和行裁剪,ORC Stripe或Parquet RowGroup一般要读取多个IO range, 这里需要根据一定的阈值对相邻的IO range进行合并,避免远程IO请求过多影响整体读取性能。
- Text: Text的读取模式是顺序读。Text格式不存在行裁剪和列裁剪优化,因此异步IO模型只需读取连续且相邻的IO range。在处理当前文件段时,可通过异步IO模型来读取下一个文件段的数据。等到处理下个文件段时,数据已经在内存中了。
文件分区读
我们知道,Spark为了提升task的并行度,会将HDFS file拆分成多个file split,每个任务读取一个file split,从而提升任务的并行度。对于ORC和Parquet格式,这些file split可以对应到一个或多个Stripe或Row Group。而对于Text格式,一个file split对应着一个文件段。
由于历史原因,我们的生产环境存在一些Text格式的Hive表,它们通常使用bzip2压缩算法。但是在CH实现中,bzip2压缩文件不支持分区读,这限制了Spark任务的并行度。我们在Gluten中扩展了bzip2的分区读功能,实现了对bzip2文件任意范围的分区读。
注意,分区读虽然能提升任务的并行度,但是需要妥善处理好两个相邻file split之间的边界问题。当然ORC/Parquet列式存储不存在这种担忧。但是在Text格式中,file split边界和行边界的错位可能会导致数据不完整或数据错乱,如果再叠加上bzip2压缩,要处理的边界问题会更加复杂,需要考虑file split边界、行边界、bzip2压缩块边界在不同位置下的情况,保证数据不多不少不错。
计算优化
在Spark任务中,CPU计算占据了大部分的执行时间,因此计算优化是提升Gluten性能的关键。在实际优化中,我们一方面替换更高效的底层算法或第三方库,另一方面通过大循环的执行效率
替换更高效的算法或库
Native Engine底层依赖了大量的第三方库或算法。以CH为例,读取ORC文件依赖arrow和orc库, 读取HDFS文件依赖libhdfs3, JSON解析依赖simdjson和rapidjson,实现join算法有单线程的hash join、并行的parallel hash join、支持spill功能的grace hash join、sort merge join等。
通过替换更高效的算法或库,可以在改动较小的情况下,优化系统的性能。 例如
- CH中默认使用simdjson替代rapidjson来解析JSON文件,simdjson是一个基于SIMD指令集的高性能JSON解析库,它的性能是后者的4倍。通过它的向量化能力大幅提高了CH中JSON相关函数的性能。
- CH中通过改进UTF8字符串函数的实现算法,提升了它们处理字符串的性能。在现实世界中,很多字符串都是ASCII字符。如果按照UTF8的方式处理ASCII字符,虽然结果没问题,但是无法利用CPU向量化的能力。我们实现了自适应算法:对于一个输入字符串向量,首先通过SIMD指令判断其中是否包含非ASCII字符,如果没有,则按照ASCII字符的方式向量化的处理字符串;如果有,则使用UTF8字符的方式处理字符串。
大循环优化
在Native Engine中,CPU计算主要体现在大循环上。通常情况下,我们在一个大循环中读取一个或多个输入向量,并且将结果填充到输出向量中,循环中每次迭代对应着输入输出向量中的一行数据。在Gluten中,CH处理向量的默认batch size是8192,在这个量级下,循环中任何微小的性能瑕疵都会影响大循环的整体性能,反过来说,循环中任何一个了不起眼的小优化都可能带来显著的性能提升。
优化大循环主要从以下几个方面入手:
消除分支
关于大循环中分支对性能的危害性,我们在前面已经介绍。
以下是几种解决方案:
- branchless编程
branchless编程是指通过数学运算或位运算来替代条件分支,从而消除分支对性能的影响。在现代CPU中,乘法和加法指令的延迟都很低,通常在1-3个周期内完成,而分支指令的延迟可能高达几十个周期,因此在大循环中branchless优化带来的收益还是很明显的。
例1
size_t a_index = 0, b_index = 0;
for (size_t i = 0; i < n; ++i) {
c[i] = cond[i] ? static_cast<T>(a[a_index++]) : static_cast<T>(b[b_index++]);
}
通过branchless优化后:
size_t a_index = 0, b_index = 0;
for (size_t i = 0; i < n; ++i) {
c[i] = static_cast<T>(a[a_index]) * !!cond[i] + static_cast<T>(b[b_index]) * !cond[i];
a_index += !cond[i];
b_index += !!cond[i];
}
其中``!!cond[i]和!cond[i]`分别将条件转换为0或1,从而实现了条件分支的数学计算。
例2
for (size_t i = 0; i < n; ++i) {
c[i] = (a[i] > 10) && (b[i] < 20);
}
&&逻辑与计算会在底层汇编代码中引入分支跳转。为了消除分支跳转
我们可以将逻辑与转化为数学计算
for (size_t i = 0; i < n; ++i) {
c[i] = (a[i] > 10) & (b[i] < 20);
}
注意,clang或gcc编译器在开启-O2或更高优化级别时,会将一些简单的分支逻辑自动优化为branchless代码,如将三目运算符转化成cmov指令。因此当你在开启branchless优化之前,请先检查编译器是否已进行过自动优化,推荐使用Compiler Explorer来查看指定编译器和编译选项下生成的汇编代码。
bithacks中介绍了一系列位运算技巧,可以帮我我们消除分支跳转。
- 分支上提到循环外
分支上提是指将循环中的分支判断移到循环外部,从而减少循环中的分支判断次数。这样可以减少分支预测失败的概率,提高CPU流水线的效率。
这里有一个实际的例子
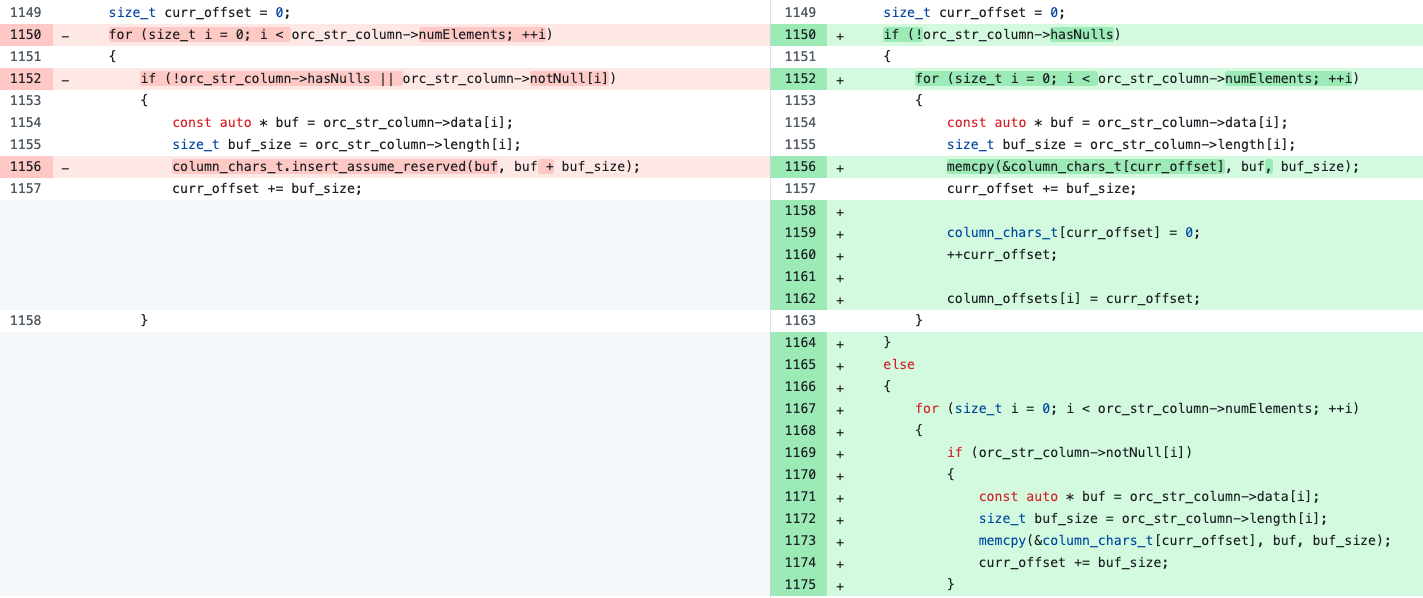
以上是CH中orc reader将orc string列转化为CH string列的代码片段。
在优化前,循环中的if-else条件引入了3个branch,如果if条件为true, 对应行中string值非Null,按照非null的方式处理,否则按照null的方式处理。if中的!orc_str_column->hasNulls是和循环无关的,在我们的改进中,将其移到了循环外部。改进后一个循环分裂成了两个循环,第一个循环处理所有行都非Null的情况,第二个循环处理其他情况,第一个循环没有分支跳转,第二个循环只有2个branch。
消除虚函数调用
虚函数常用于实现多态中的动态绑定,它允许在运行时根据对象的实际类型调用相应的函数。然而,虚函数调用会引入额外的开销,如指针间接寻址、分支预测失败、无法内联优化等。大循环中中的虚函数调用绝对是性能杀手。
- 通过CRTP(Curiously Recurring Template Pattern)进行devirtualize
CRTP是一种C++编程技巧,它允许在编译时确定类型,从而消除虚函数调用的开销。通过CRTP,我们可以将虚函数调用转化为静态多态,从而避免了指针间接寻址和分支预测失败的问题。
还是以CH中向量的实现为例, IColumn定义了CH中向量的接口,CH中所有向量的实现都集成自IColumn,如ColumnVector, ColumnString, ColumnArray等。IColumn中定义了两个虚函数接口
fillFromBlocksAndRowNumbers,用于从多个Block和行号填充向量的值, 这是一个批量计算操作。insertFrom,用于将其他向量的某个元素插入到当前向量中。
/// Declares interface to store columns in memory.
class IColumn : public COW<IColumn>
{
public:
/// Appends n-th element from other column with the same type.
/// Is used in merge-sort and merges. It could be implemented in inherited classes more optimally than default implementation.
virtual void insertFrom(const IColumn & src, size_t n);
/// Fills column values from list of blocks and row numbers
/// `blocks` and `row_nums` must have same size
virtual void fillFromBlocksAndRowNumbers(const DataTypePtr & type, size_t source_column_index_in_block, const std::vector<const Block *> & blocks, const std::vector<UInt32> & row_nums);
};
/// Fills column values from list of blocks and row numbers
/// Implementation with concrete column type allows to de-virtualize col->insertFrom() calls
template <typename ColumnType>
static void fillColumnFromBlocksAndRowNumbers(ColumnType * col, const DataTypePtr & type, size_t source_column_index_in_block, const std::vector<const Block *> & blocks, const std::vector<UInt32> & row_nums)
{
chassert(blocks.size() == row_nums.size());
col->reserve(col->size() + blocks.size());
for (size_t j = 0; j < blocks.size(); ++j)
{
if (blocks[j])
col->insertFrom(*blocks[j]->getByPosition(source_column_index_in_block).column, row_nums[j]);
else
type->insertDefaultInto(*col);
}
}
/// Fills column values from list of blocks and row numbers
void IColumn::fillFromBlocksAndRowNumbers(const DataTypePtr & type, size_t source_column_index_in_block, const std::vector<const Block *> & blocks, const std::vector<UInt32> & row_nums)
{
fillColumnFromBlocksAndRowNumbers(this, type, source_column_index_in_block, blocks, row_nums);
}
可以看到IColumn::fillFromBlocksAndRowNumbers的实现中调用了fillColumnFromBlocksAndRowNumbers函数,而后者是一个模板函数,传入fillColumnFromBlocksAndRowNumbers中的col参数类型是IColumn *, 大循环中的col->insertFrom调用是虚函数调用!
为了去除循环中col->insertFrom虚函数调用开销,CH引入了IColumnHelper类,它是一个CRTP类模板,继承自IColumn。模板中override了fillFromBlocksAndRowNumbers方法,提供了一个更高效的实现。
// Implement methods to devirtualize some calls of IColumn in final descendents.
/// `typename Parent` is needed because some columns don't inherit IColumn directly.
/// See ColumnFixedSizeHelper for example.
template <typename Derived, typename Parent = IColumn>
class IColumnHelper : public Parent
{
public:
/// Fills column values from list of blocks and row numbers
/// `blocks` and `row_nums` must have same size
void fillFromBlocksAndRowNumbers(const DataTypePtr & type, size_t source_column_index_in_block, const std::vector<const Block *> & blocks, const std::vector<UInt32> & row_nums) override;
};
/// Fills column values from list of blocks and row numbers
template <typename Derived, typename Parent>
void IColumnHelper<Derived, Parent>::fillFromBlocksAndRowNumbers(const DataTypePtr & type, size_t source_column_index_in_block, const std::vector<const Block *> & blocks, const std::vector<UInt32> & row_nums)
{
auto & self = static_cast<Derived &>(*this);
fillColumnFromBlocksAndRowNumbers(&self, type, source_column_index_in_block, blocks, row_nums);
}
在调用静态模板函数fillColumnFromBlocksAndRowNumbers前,IColumnHelper::fillFromBlocksAndRowNumbers首先会将this指针转换为Derived*类型,Derived是IColumnHelper的派生类类型。通过引入CRTP,我们可以在编译期确定循环中col->insertFrom的具体类型,从而消除insertFrom的虚函数调用开销。【相关PR](https://github.com/ClickHouse/ClickHouse/pull/77350)
类型特化处理
类型特化处理也是在CH中广泛使用的优化技巧。它的核心思想是,每次处理IColumn*类型的向量前,先判断向量的具体类型,然后根据具体类型调用不同的处理函数,相当于把循环中的动态绑定逻辑,转移到循环外部。这样循环中的虚函数调用开销就消失了,虽然循环外部增加了一个类型判断的开销,但是由于循环外部的类型判断只执行一次,而循环内部的虚函数调用可能会执行数千次,新增的类型判断开销显得微不足道。
还是以CH为例,如下所示,ColumnArray表示CH中的数组向量,ColumnArray::filter方法用于对数组向量进行过滤操作。ColumnArray在编译期是无法知晓其嵌套类型的,因此在filter方法中需要根据data的具体类型进行判断,然后调用不同的处理函数,在这些处理函数中,会将data转换为具体的向量类型,执行响应的过滤操作。
ColumnPtr ColumnArray::filter(const Filter & filt, ssize_t result_size_hint) const
{
if (typeid_cast<const ColumnUInt8 *>(data.get()))
return filterNumber<UInt8>(filt, result_size_hint);
if (typeid_cast<const ColumnUInt16 *>(data.get()))
return filterNumber<UInt16>(filt, result_size_hint);
if (typeid_cast<const ColumnFloat32 *>(data.get()))
return filterNumber<Float32>(filt, result_size_hint);
if (typeid_cast<const ColumnFloat64 *>(data.get()))
return filterNumber<Float64>(filt, result_size_hint);
if (typeid_cast<const ColumnDecimal<Decimal32> *>(data.get()))
return filterNumber<Decimal32>(filt, result_size_hint);
if (typeid_cast<const ColumnDecimal<Decimal64> *>(data.get()))
return filterNumber<Decimal64>(filt, result_size_hint);
if (typeid_cast<const ColumnString *>(data.get()))
return filterString(filt, result_size_hint);
}
template <typename T>
ColumnPtr ColumnArray::filterNumber(const Filter & filt, ssize_t result_size_hint) const
{
using ColVecType = ColumnVectorOrDecimal<T>;
if (getOffsets().empty())
return ColumnArray::create(data);
auto res = ColumnArray::create(data->cloneEmpty());
auto & res_elems = assert_cast<ColVecType &>(res->getData()).getData();
Offsets & res_offsets = res->getOffsets();
filterArraysImpl<T>(assert_cast<const ColVecType &>(*data).getData(), getOffsets(), res_elems, res_offsets, filt, result_size_hint);
return res;
}
提前分配内存
在大循环中,如果每次迭代都需要动态分配内存,会频繁调用realloc函数,造成page-fault和cache miss,严重影响循环的执行效率。为了避免这种情况,我们可以在大循环开始前,提前统计并分配好足够的内存空间。不管是表达式计算中使用的向量,还是join/aggregate算子中使用的hash table,都可通过提前分配内存来减少频繁的内存分配和释放操作,从而提升性能。
如下所示,vector是个静态方法,用于对输入字符串向量执行trim操作。在for循环开始填充输出向量之前,首先对res_data和res_offsets进行预分配,确保它们有足够的内存空间来存储结果,避免了在循环中频繁调用realloc函数。
class FunctionTrim : public IFunction
{
public:
static void vector(
const ColumnString::Chars & input_data,
const ColumnString::Offsets & input_offsets,
const std::optional<SearchSymbols> & custom_trim_characters,
ColumnString::Chars & res_data,
ColumnString::Offsets & res_offsets,
size_t input_rows_count)
{
res_offsets.resize_exact(input_rows_count);
res_data.reserve_exact(input_data.size());
size_t prev_offset = 0;
size_t res_offset = 0;
const UInt8 * start;
size_t length;
for (size_t i = 0; i < input_rows_count; ++i)
{
execute(reinterpret_cast<const UInt8 *>(&input_data[prev_offset]), input_offsets[i] - prev_offset - 1, custom_trim_characters, start, length);
res_data.resize(res_data.size() + length + 1);
memcpySmallAllowReadWriteOverflow15(&res_data[res_offset], start, length);
res_offset += length + 1;
res_data[res_offset - 1] = '\0';
res_offsets[i] = res_offset;
prev_offset = input_offsets[i];
}
}
};
选择合适的内存分配器并配置内存分配策略也能提升内存分配的效率,CH中默认使用jemalloc作为内存分配器。jemalloc是一个高性能的内存分配器,它通过多线程和分区策略来减少内存碎片和锁竞争,从而提高内存分配的效率。jemalloc可通过环境变量JEMALLOC_CONF进行配置,如设置分配器的线程数、分区大小、归还内存到OS的策略等。在CH中,默认的jemalloc配置是percpu_arena:percpu,oversize_threshold:0,muzzy_decay_ms:0,dirty_decay_ms:5000,prof:true,prof_active:false,background_thread:true,lg_extent_max_active_fit:8。在其他系统中可根据内存分配的特点和需求对MALLOC_CONF进行调整。
Memory Prefetch
Memory Prefetch是指在循环中提前加载下一次需要访问的数据到CPU缓存中,从而减少cache miss的概率,提高内存访问的性能。Memory Prefetch可以通过编译器内置的__builtin_prefetch函数来实现。在CH中,基于向量的计算一般是顺序访问,cache-miss概率较低,在此种场景中Memory Prefetch的效果并不明显。
但是在一些随机访问或非顺序访问的场景中,Memory Prefetch可以显著提高性能,最典型的例子就是CH中的aggregate算子,在聚合过程中,在处理当前行的group by key时,会提前获取固定步长后对应行的group by key,计算其哈希值,并根据哈希值找到hash table中对应bucket,使用__builtin_prefetch将bucket加载到CPU缓存中。这样下次处理被prefetch的行时,对应的bucket已经在CPU缓存中,避免了cache miss的开销。
/// For all rows.
for (size_t i = row_begin; i < row_end; ++i)
{
if constexpr (prefetch && HasPrefetchMemberFunc<decltype(method.data), KeyHolder>)
{
if (i == row_begin + PrefetchingHelper::iterationsToMeasure())
prefetch_look_ahead = prefetching.calcPrefetchLookAhead();
if (i + prefetch_look_ahead < row_end)
{
auto && key_holder = state.getKeyHolder(i + prefetch_look_ahead, *aggregates_pool);
method.data.prefetch(std::move(key_holder));
}
}
state.emplaceKey(method.data, i, *aggregates_pool).setMapped(place);
}
template <typename KeyHolder>
void ALWAYS_INLINE prefetch(KeyHolder && key_holder) const
{
const auto & key = keyHolderGetKey(key_holder);
const auto key_hash = hash(key);
prefetchByHash(key_hash);
}
void ALWAYS_INLINE prefetchByHash(size_t hash_key) const
{
const auto place = grower.place(hash_key);
__builtin_prefetch(&buf[place]);
}
向量化优化
以CH和Velox为代表的Native Engine,相比基于JVM的Vanilla Spark性能更快的重要原因就是,他们使用Native语言C++编写,能够充分利用CPU的SIMD指令集来进行向量化计算,SIMD指令集允许在单条指令中同时处理多个数据元素,从而大幅提升计算性能。向量化优化主要有两种方式
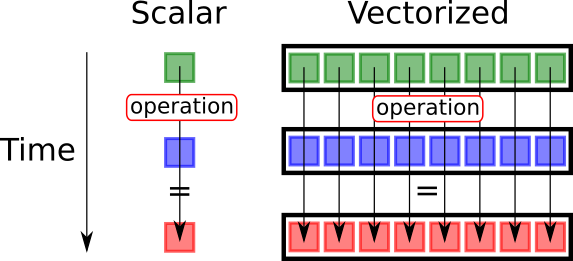
- 编译器自动向量化
编译器自动向量化是指编译器在编译时自动将循环中的标量操作优化成SIMD指令。
以下是一个编译器自动向量化的例子,我们可以看到,循环中标量操作c[i] = a[i] + b[i]被clang编译器自动优化成了SIMD指令paddd,该指令操作128位XMM寄存器中的4个32位整数,等价于同时对4个整数进行加法操作。
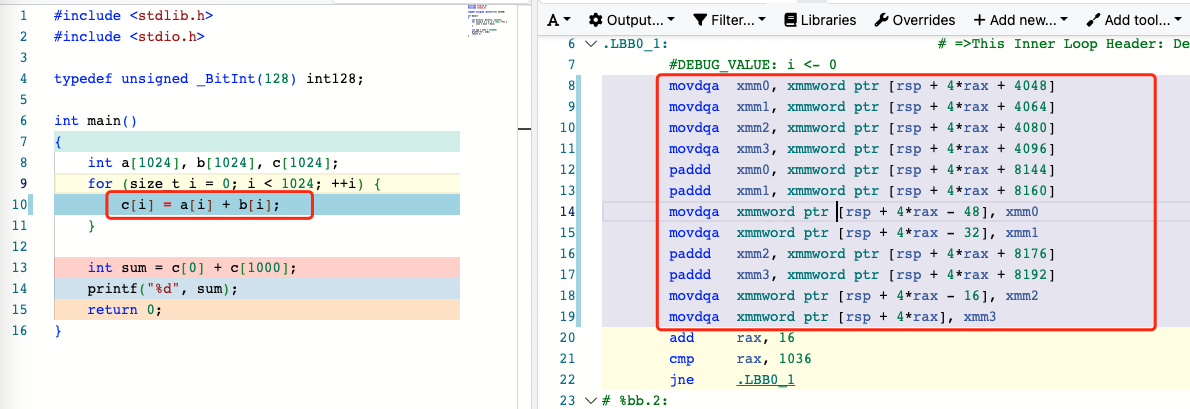
编译器会对满足条件的循环进行自动向量化优化。作为开发者,我们如何确定循环是否被编译器自动向量化了呢?有两种方法
- 添加编译器选项,让clang或gcc在编译过程中输出向量化优化信息,循环代码是否被自动向量化了,如果没有,原因是什么。
- 使用工具(Compiler Explorer、gdb或Intel Vtune)查看编译器生成的汇编代码,检查循环中是否存在SIMD指令。这里推荐使用Intel Vtune,可视化功能做的比较好,方便查看源代码和对应的汇编码。
CH和Gluten中有很多通过branchless编程移除循环中分支,从而使得编译器成功自动向量化的例子。如下:
优化前
const ColumnNullable & condition_nullable = assert_cast<const ColumnNullable &>(*instruction.condition);
const ColumnUInt8 & condition_nested = assert_cast<const ColumnUInt8 &>(condition_nullable.getNestedColumn());
const auto & condition_nested_data = condition_nested.getData();
const NullMap & condition_null_map = condition_nullable.getNullMapData();
for (size_t row_i = 0; row_i < rows; ++row_i)
{
/// Equivalent to below code. But it is able to utilize SIMD instructions.
/// if (!condition_null_map[row_i] && condition_nested_data[row_i])
/// inserts[row_i] = i;
inserts[row_i] += (~condition_null_map[row_i] & (!!condition_nested_data[row_i])) * (i - inserts[row_i]);
}
- 手动向量化
手动向量化是指开发者在循环中显式使用SIMD指令来进行向量化计算。目前CH中是用Intel Intrinsics来编写x86上的SIMD指令,用NEON-intrinsics编写ARM上的SIMD指令。手动向量化需要开发者对SIMD指令集有一定的了解。
C++最新标准也引入了SIMD的支持std::experimental::simd,它是一个可移植的SIMD编程接口,目前只是实验特性,期待早日成为C++26标准的一部分。
CH中的向量化实现了cpu dispatch极致,有了它之后,用户无需在编译期决定使用哪种SIMD指令集,CH会在运行时根据CPU支持的指令级列表选择最优的SIMD指令集(SSE4.2、AVX2、AVX512等)来执行向量化计算。
以下是Gluten中实现spark floor函数的代码片段,它使用了avx2指令级来实现对Float32类型的向量化处理,一次迭代中可同时处理8个连续的Float32。其中_mm256_loadu_ps加载数据到AVX2寄存器,使用_mm256_cmp_ps进行比较操作,使用_mm256_blendv_ps进行条件选择,最后使用_mm256_storeu_ps将结果存储回内存。
void checkFloat32AndSetNullables(Float32 * data, UInt8 * null_map, size_t size) {
const __m256 inf = _mm256_set1_ps(INFINITY);
const __m256 neg_inf = _mm256_set1_ps(-INFINITY);
const __m256 zero = _mm256_set1_ps(0.0f);
size_t i = 0;
for (; i + 7 < size; i += 8)
{
__m256 values = _mm256_loadu_ps(&data[i]);
__m256 is_inf = _mm256_cmp_ps(values, inf, _CMP_EQ_OQ);
__m256 is_neg_inf = _mm256_cmp_ps(values, neg_inf, _CMP_EQ_OQ);
__m256 is_nan = _mm256_cmp_ps(values, values, _CMP_NEQ_UQ);
__m256 is_null = _mm256_or_ps(_mm256_or_ps(is_inf, is_neg_inf), is_nan);
__m256 new_values = _mm256_blendv_ps(values, zero, is_null);
_mm256_storeu_ps(&data[i], new_values);
UInt32 mask = static_cast<UInt32>(_mm256_movemask_ps(is_null));
for (size_t j = 0; j < 8; ++j)
{
UInt8 null_flag = (mask & 1U);
null_map[i + j] = null_flag;
mask >>= 1;
}
}
for (; i < size; ++i)
checkAndSetNullable(data[i], null_map[i]);
}
代码生成
在OLAP数仓领域,代码生成一般和向量化优化相提并论。在论文Everything You Always Wanted to Know About Compiled and Vectorized Queries But Were Afraid to Ask中,作者比较了代码生成和向量化执行模型的性能。结果表明,代码生成在计算密集型查询方面表现更好, 因为它能够将数据保留在寄存器中,从而需要执行的指令更少。而向量化执行在隐藏并行cache-miss方面表现略好一些,因此在访问用于聚合或连接的大哈希表的内存受限查询中具有一定优势。在实际的工程实践中,可将二者结合使用。CH便是一个很好的例子。
考虑这样的表达式a / b + c / d + e / f + g / h + i / j, 该表达式对应的DAG比较大,如果使用向量化执行模型,会生成大量的中间结果向量(如a / b的结果向量、c / d的结果向量),并对它们进行读写,在此过程中产生了大量的page-fault和cache-miss,导致性能下降。而代码生成则会将整个表达式编译成一段机器码,直接在寄存器中计算结果,避免了中间结果写入/读出内存的开销。
代码生成的逻辑示意:
for (size_t i = 0; i < n; ++i)
{
res[i] = a[i] / b[i] + c[i] / d[i] + e[i] / f[i] + g[i] / h[i] + i[i] / j[i];
}
在CH中,代码生成是通过LLVM IR来实现的。CH中首先识别表达式中函数和参数类型是否支持JIT优化,如果支持,则将表达式转化成LLVM IR代码,然后使用LLVM将IR代码编译成机器码,缓存机器码到内存中。在执行阶段,CH会直接调用编译好的机器码来执行对应的表达式计算,而不是通过向量化模型解释执行。目前CH中支持int, float, double等基本类型的代码生成,支持的算子有project、filter、aggregate和sort。我们在Gluten + CH的优化中对JIT的功能进行了扩展,支持了更多的表达式和基本类型,目前该功能正在贡献给CH社区。
评估优化效果
优化完成后,评估优化效果是性能优化流程中至关重要的一环。只有通过科学、系统的评估,才能确认优化措施是否真正带来了预期的性能提升,避免“自嗨式优化”或因环境变化导致的误判。
评估过程建议分为开发环境和生产环境两个阶段,形成完整的闭环。
在开发环境中,首先要对优化前后的代码进行对比测试。此阶段的目标是快速、低成本地验证优化措施的有效性,并排除外部环境的干扰,可使用前面提到的Benchmark工具比对优化前后性能。开发环境评估的优势在于可控性强、调试方便,适合快速迭代和定位问题。但由于数据规模、并发压力等与生产环境存在差异,开发环境的评估结果仅作为初步参考。
开发环境验证通过后,优化措施需要在生产环境进行真实负载下的性能评估,生产环境更能体现性能优化的实际效果。
评估优化效果不是一次性的工作,而是一个持续的闭环过程。每次优化后,都要将评估结果与预期目标进行对比。如果效果未达预期,需要回到前面的分析和优化阶段,重新定位瓶颈、调整优化策略,直至达到目标。这个闭环过程确保了性能优化的科学性和有效性,避免了盲目优化和资源浪费。
书籍推荐
- 《Performance Analysis and Tuning on Modern CPUs》
- 《Optimizing Software in C++》
- 《性能之巅》
- 《BPF之巅》
- 《Extensible Query Optimizers in Practice》
参考
文章作者 后端侠
上次更新 2025-05-28