Gluten+CH backend性能优化--问题与挑战篇
文章目录
问题与挑战
前篇中介绍了我们在Gluen + CH backend功能支持上的工作。但是我们发现,即使所有算子或表达式都能够从vanilla spark offload到Gluten中执行,在少数场景下性能还不是很可观,表现为和vanilla spark持平甚至低于它。因此,在功能完备的前提下,我们要对Gluten的性能进行专项优化。根据我们对生产环境的观察,Gluten的性能瓶颈主要在于CPU、Memory和网络IO。以下将展开讲讲导致这些瓶颈的原因。
同步远程IO
IO方面的问题主要体现在
- 离线ETL场景中,IO请求次数和数据量都很大
出于成本考虑,我们的基础设施层自建机房和自运维服务器,使用Apache Hive/HDFS + Yarn + Spark架构来支持业务进行批量数据分析和处理。我们在Spark中的工作负载主要是离线ETL任务,其中的IO占比显著比OLAP要高。每个spark executor中的scan算子都会访问HDFS集群中的Hive表。这其中涉及到大量的IO请求。
我们知道,在Hive表写文件时一般会设置对文件的压缩, 例如ORC格式中会按照一个固定的阈值(compression block size)对列式数据进行压缩,Parquet格式中会在Page数据从内存写入到磁盘前对其进行压缩, Page默认大小1MB,而Text格式则会对文件整体进行压缩。因此IO读取的数据量越大,解压缩的代价也就越大。因此影响scan算子性能的不止是IO, 还有decompress。
- 同步IO模型阻塞CPU计算
CH backend中使用libhdfs3库访问HDFS集群,libhdfs3中的hdfsRead是同步阻塞调用,每次读取的延迟在毫秒量级。
HDFS文件大概有三种格式,他们的读取模式如下:
- ORC/Parquet: 列式存储,需要多次小范围随机读(如读取Footer、 Index等元数据)
- Text:行式存储,基本是顺序读,当file split很大时读取频繁
CH的同步模型决定了,在读取HDF文件时大量的读操作都会阻塞工作线程,造成CPU空闲。
- 压缩文件(bzip2)无法分区读
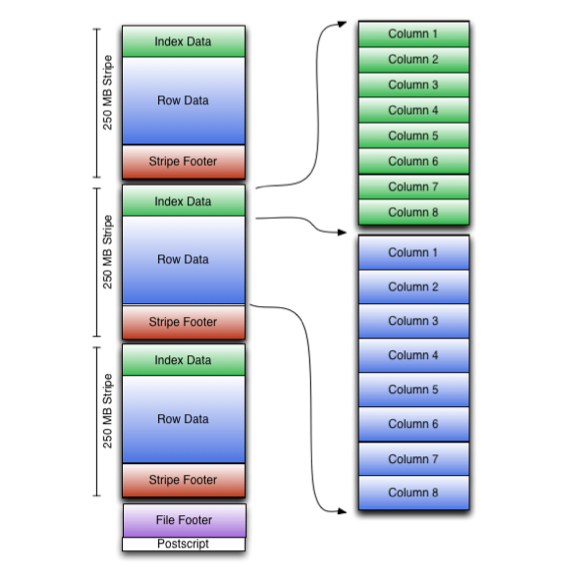
Spark为了提升task的并行度,会将HDFS file拆分成多个file split,每个任务读取一个file split,从而. 对于ORC来说, 一个file split可能对应着一个或多个Stripe, 对Parquet来说,一个file split对应一个或多个Row Group。对Text格式来说,一个file split对应着一个文件段。
bzip2是一种常用的文件压缩格式,它是vanilla spark中唯一支持分区读的压缩格式。但是在Gluten中尚未实现对bzip2的分区读,这就导致了在Gluten中一个分区必须读取至少一个bzip2文件并对其进行解压,当bzip2文件非常大(GB量级)时,scan算子成为拖慢整个查询的瓶颈。
计划优化不充分
Vanilla Spark中其实已经有很多执行计划的优化规则,如合并project、谓词下推,嵌套列裁剪等。在Gluten中,虽然也能利用这些优化规则,但是在某些场景下最终下发给CH Backend的计划未必是最优的。原因主要有以下几点
CH虽然也自带很多优化规则,但是大部分对Gluten不生效
CH自带的优化规则分为两大类,基于逻辑计划(IQueryTreeNode)优化(IQueryTreePass),和基于物理计划(IQueryPlanStep)优化(QueryPlanOptimizations)。由于Gluten是直接将substrait plan转成CH的物理计划,因此无法利用CH自带的基于逻辑计划的优化规则。另外CH自带的基于物理计划的优化规则中,有很多是针对MergeTree的,对Gluten没有意义。Spark中表达式层面的优化是在jvm执行阶段完成的,对Gluten没意义。
例如,spark查询中的CSE(Common Subexpression Elimination)优化是在物理执行阶段的Whole-Stage Codegen中进行的,这个阶段的优化当然不会对Gluten生效。
explain formatted select hash(id), hash(id)+1, hash(id)-1 from range(10)
+----------------------------------------------------+
| plan |
+----------------------------------------------------+
| == Physical Plan ==
CHNativeColumnarToRow (4)
+- ^ ProjectExecTransformer (2)
+- ^ CHRangeExecTransformer (1)
(1) CHRangeExecTransformer
Output [1]: [id#5L]
Arguments: 0, 10, 1, 1, 10, [id#5L]
(2) ProjectExecTransformer
Output [3]: [hash(id#5L, 42) AS hash(id)#6, (hash(id#5L, 42) + 1) AS (hash(id) + 1)#7, (hash(id#5L, 42) - 1) AS (hash(id) - 1)#8]
Input [1]: [id#5L]
(3) WholeStageCodegenTransformer (1)
Input [3]: [hash(id)#6, (hash(id) + 1)#7, (hash(id) - 1)#8]
Arguments: false
(4) CHNativeColumnarToRow
Input [3]: [hash(id)#6, (hash(id) + 1)#7, (hash(id) - 1)#8]
可以看到,虽然hash(id)是重复子表达式,它在ProjectExecTransformer算子中被计算了3次,而实际上只需要计算一次。
- 生产环境有些corner case, 未必能被Spark优化规则覆盖。
以下是生产环境的简化case, 首先在本地创建orc表,并查看查询计划:
CREATE TABLE aj (
country STRING,
event STRUCT < time: BIGINT, lng: BIGINT, lat: BIGINT, net: STRING, log_extra: MAP < STRING, STRING >, event_id: STRING, event_info: MAP < STRING, STRING > >
)
USING
orc;
explain formatted
SELECT
*
FROM
(
SELECT
game_name,
CASE
WHEN event.event_info [ 'tab_type' ] IN (5) THEN '1'
ELSE '0'
END AS entrance
FROM
aj
LATERAL VIEW explode(split(country, ', ')) game_name AS game_name
WHERE
event.event_info [ 'action' ] IN (13)
)
WHERE
game_name = 'xxx';
我们可以看到,event是一个struct字段,查询中只依赖了event.event_info这个子字段,但是其查询计划中scan算子却读取了其他所有子字段,即Spark自带的嵌套列裁剪规则并没有覆盖上面的case。
(1) ScanTransformer orc default.aj
Output [2]: [country#41, event#42]
Batched: true
Location: InMemoryFileIndex [file:/data1/liyang/cppproject/spark/spark-3.3.2-bin-hadoop3/spark-warehouse/aj]
PushedFilters: [IsNotNull(event.event_info)]
ReadSchema: struct<country:string,event:struct<time:bigint,lng:bigint,lat:bigint,net:string,log_extra:map<string,string>,event_id:string,event_info:map<string,string>>>
读取了不必要的子字段会导致
- 更多的IO请求次数和数据量
- 解压缩消耗更多CPU
- 计算消耗更多CPU和Memory
- Spark和CH实现的差异性导致经过Spark规则优化的计划在CH中仍有进一步优化的空间。
如:Spark中and或or等逻辑计算只接受两个参数,但是在CH中,他们可接受多个参数。考虑查询中过滤条件有and或or的嵌套情况,如and(and(and(cond1, cond2), cond3), cond4), 在CH backend中有优化成and(cond1, cond2, cond3, cond3)。在CH中,相比前者,后者的优势在于能减少中间结果列的物化代价,从而提升表达式的计算性能。
CPU执行效率不高
我们知道,Gluten项目的初心就是利用Native Engine的向量化能力,充分压榨CPU,从而获得比基于JVM的查询引擎更好的性能。因此提高CPU执行效率,对提升Gluten的性能至关重要。
在Native Engine中,影响CPU执行效率的因素有
低效的算法或库实现
在native engine中,即便硬件资源充足,低效的算法或库实现仍然可能成为系统的性能瓶颈。
例1: CH早期的hash join算子不支持并行执行,hash join算子的build side和probe side并行度必须为1,这使得大数据量下join成为性能瓶颈。后来我们实现了parallel hash join算法,build side可并行hash table, probe side也是并行的,每个线程内对输入Block行scatter,得到多个分区的Block,再为每个分区的Block执行probe, 最终将每个分区的join结果合并。后来社区基于parallel hash join进一步进行了优化, 优化后build side每个线程并行构建two level hash table的的部分bucket, 在build结束之后将每个线程构建的结果进行零代价的合并,得到全局的two level hash table。得益于此,probe side无需进行scatter, 这避免了分区和合并的巨大开销。
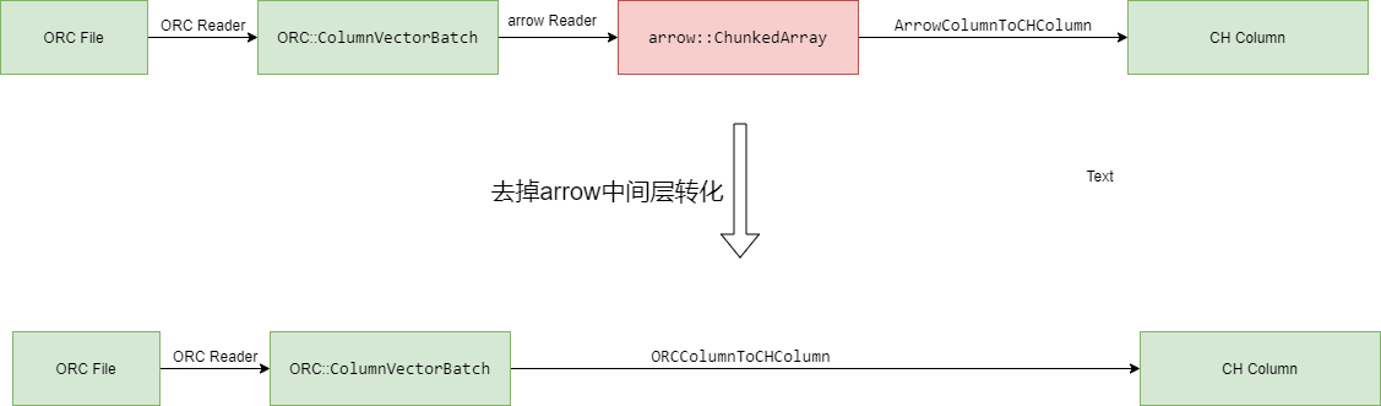
例2: CH早期的orc reader调用的arrow C++库来读取orc文件,但是整个过程会对列式数据做几层转换:首先将orc列式结构转化为arrow中的列式结构,再将arrow的列式结构转化为CH的列式结构。实际上,如果我们启用arrow库,直接使用orc库,中间这一层转换开销就可以去掉。
低效的循环
Native Engine通过循环处理列式数据的每一行。例如
for (size_t i = 0; i < rows; ++i)
{
/// Process inputs
...
/// Assign output
result[i] = ...
}
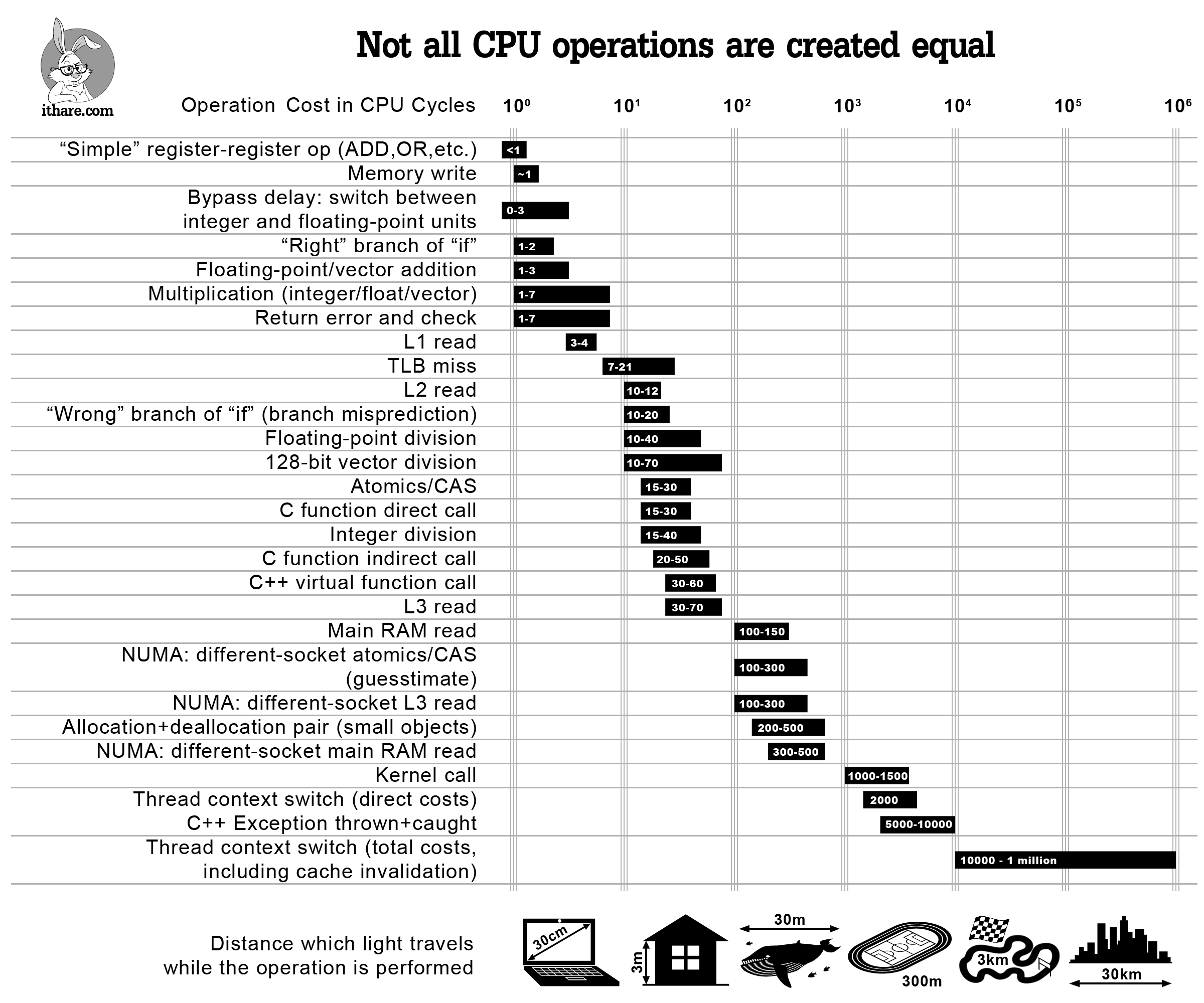
Gluten中默认一个列块的最大行数是8192, 在这个量级的循环下,循环体内任何一个微小的性能瑕疵都可能会被放大,进而影响整体的执行效率。这些因素包括
branch-miss
现代CPU采用流水线并行+分支预测的方式执行指令,分支预测失败会导致流水线清空,产生十几个周期的性能惩罚。而且条件分支还会阻碍编译器的自动向量化优化,无法使用SIMD指令来加速循环。
for (size_t i = 0; i < src_vec->size(); ++i)
{
F element = src_vec->getElement(i);
if (isNaN(element) || !isFinite(element))
null_map_data[i] = 1;
else if (element > int_max_value)
data[i] = int_max_value;
else if (element < int_min_value)
data[i] = int_min_value;
else
data[i] = static_cast<T>(element);
}
以上是gluten中一段优化前的代码,循环体内引入了四个分支,严重影响了循环体的性能。经过优化消除分支后,性能是优化前的2.67
cache-miss
CPU采用多级缓存(L1/L2/L3)以缓解CPU与主存之间的速度鸿沟。当CPU请求的数据不在当前缓存层级时即发生缓存未命中,需向下一级存储发起访问,这种情况成为cache-miss。当数据不在L1/L2/L3 cache中时,需要向内存发起访问,此为LLC-miss。
cache-miss是有代价的,访问L1 cache只需要几个CPU cycles, 访问L2 cache需要十几个cycles, 访问L3 cache需要几十个cycles, 而访问内存需要上百个cycles。因此cache-miss尤其是LLC-miss会造成严重的性能下降。
cache miss的情况容易发生在aggregate或join算子的hash table的随机访问中。
// 行优先遍历(缓存友好)
for (int i = 0; i < ROWS; i++) {
for (int j = 0; j < COLS; j++) {
sum += matrix[i][j]; // 连续内存访问,空间局部性佳
}
}
// 列优先遍历(缓存灾难)
for (int j = 0; j < COLS; j++) {
for (int i = 0; i < ROWS; i++) {
sum += matrix[i][j]; // 跳跃式访问,每次跨越行长度
}
}
indirect call
indirect call包含对虚函数的调用、对函数指针或std::function的调用。在Gluten + CH Backend中更常见的indirect call是前一种情况,即虚函数调用。C++通过虚函数调用实现了动态分发,CH中IFunction, IColumn, IProcessor, IDataType都定义了虚函数接口,方便进行各种功能扩展。
但是虚函数调用是有代价的,相比普通调用多消耗几十个cycles。虚函数调用过程如下:
- 首先程序初始化时C++会为每个包含虚函数的类生成一个虚表,每个对象实例的头部会嵌入一个指向虚表的指针vptr。
- 然后运行中调用虚函数时,会从对象的vptr找到对应类的虚表,从虚表中找到对应函数的地址,最后跳转到该地址中执行。
从cpu视角看,调用虚函数的过程包含了两次内存访问和一次函数调用,另外虚函数会阻碍其被内联优化,当虚函数体量较小时,进入函数和退出函数的额外指令对性能的影响无法忽略。
page fault
页错误是操作系统内存管理机制中的一种中断事件,当进程尝试访问的虚拟内存页未映射到物理内存时触发。page fault会导致CPU暂停当前进程的执行,转而执行操作系统的异常处理程序,将物理内存页映射到虚拟内存中, 此过程耗时us级。
在native engine中,典型的导致page fault的原因有
- 未预先分配足够多的内存,导致频繁realloc,每次realloc不仅会触发page fault, 还会导致大量memcpy。
- 内存池实现或配置不合理,导致过早归还内存给操作系统。
自动向量化失败
向量化是native engine的核心技术,向量化是指通过使用SIMD并行指令替代循环中的标量指令, 提升计算密集型任务的性能,X86下常用的SIMD指令集有SSE4、AVX2和AVX512。
当循环代码满足一定的条件时,编译器能够对循环进行自动向量化优化。但是这个条件比较苛刻,以下是导致自动向量化失败的一些常见原因:
- 循环依赖:迭代之间存在数据依赖,如循环变量之间的相互依赖或对共享变量的读写冲突。
- 条件分支:循环体内存在条件分支,使得编译器无法确定每次迭代的执行路径。
- 函数调用:循环体内调用了非内联函数或虚函数,编译器无法分析函数内部的实现。
- 指针别名:循环体内使用了指针或引用,编译器无法确定它们是否指向同一内存位置,编译器采取保守策略,放弃向量化。
其他
当然还有其他导致Gluten性能瓶颈的因素,如算子Fallback, 算子Spill。
算子Fallback会引入额外的行列转换,增加了很多不必要的计算,可通过支持该算子的列式执行解决。例如Support generate exec支持了lateral view explode算子的列式执行,不仅消除了算子Fallback, native算子的性能还是jvm中算子的3倍。
算子Spill的目的,是使executor在内存紧张的情况下,将算子中的一部分数据先从内存spill到磁盘中,待内存宽裕时再从磁盘读取到内存中。算子Spill会引入额外的IO和序列化/反序列化开销,必然会使Gluten变慢。但是在生产环境中内存资源是有限的,性能和内存占用始终是一对trade-off,除非算子本身还有改进空间。
总结
本文总结了在Gluten + CH backend 性能优化过程中的主要问题与挑战,包括同步远程IO带来的阻塞、计划优化不充分、CPU执行效率不高等方面。针对这些瓶颈,文章分析了具体原因,如同步IO模型导致CPU空闲、压缩文件分区读取受限、优化规则未完全覆盖、低效的算法实现、循环中的分支和缓存未命中、虚函数调用、页错误以及自动向量化失败等。最后指出,算子Fallback和Spill也会影响整体性能。整体来看,只有从IO、执行计划、CPU利用率等多维度持续优化,才能充分发挥Gluten + CH backend的性能优势。
参考
- vtune profiler cookbook: https://www.intel.com/content/www/us/en/docs/vtune-profiler/cookbook/2024-1/
- clickhouse performance optimizations: https://presentations.clickhouse.com/meetup63/clickhouse_performance_optimizations
文章作者 后端侠
上次更新 2025-05-23