Gluten+CH backend性能优化--案例篇
文章目录
Gluten + CH backend性能优化–案例篇
上篇中我们介绍了Gluten + CH backend中性能优化的步骤和方法。本篇我们将展开说说具体的优化案例。
IO优化
Native Reader优化
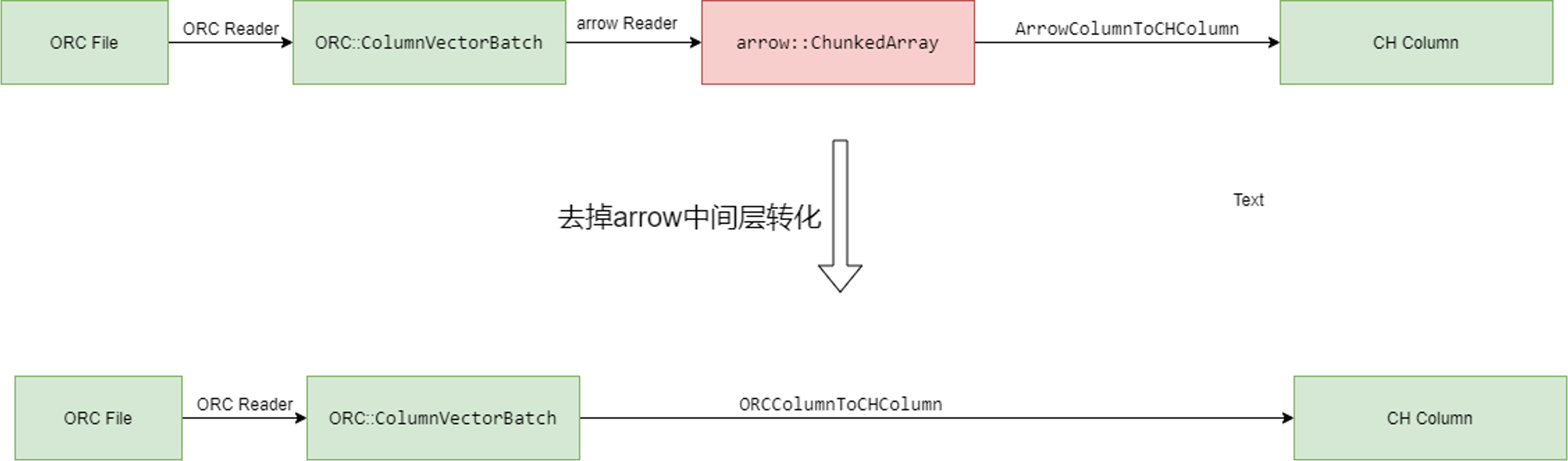
最初的时候,CH中不管是ORC还是Parquet读取, 都是通过Arrow库来实现文件读取的。但是Arrow库的读取性能并不理想,因为它在decode阶段需要将ORC或Parquet向量统一转化为Arrow中的向量,然后再转化为CH向量,多次转化导致了性能损失。
以ORC读取为例,我们生成了基于Arrow库的ORC Reader的火焰图,从中可以看到,Arrow向量转CH向量的开销占据了可观的比例。
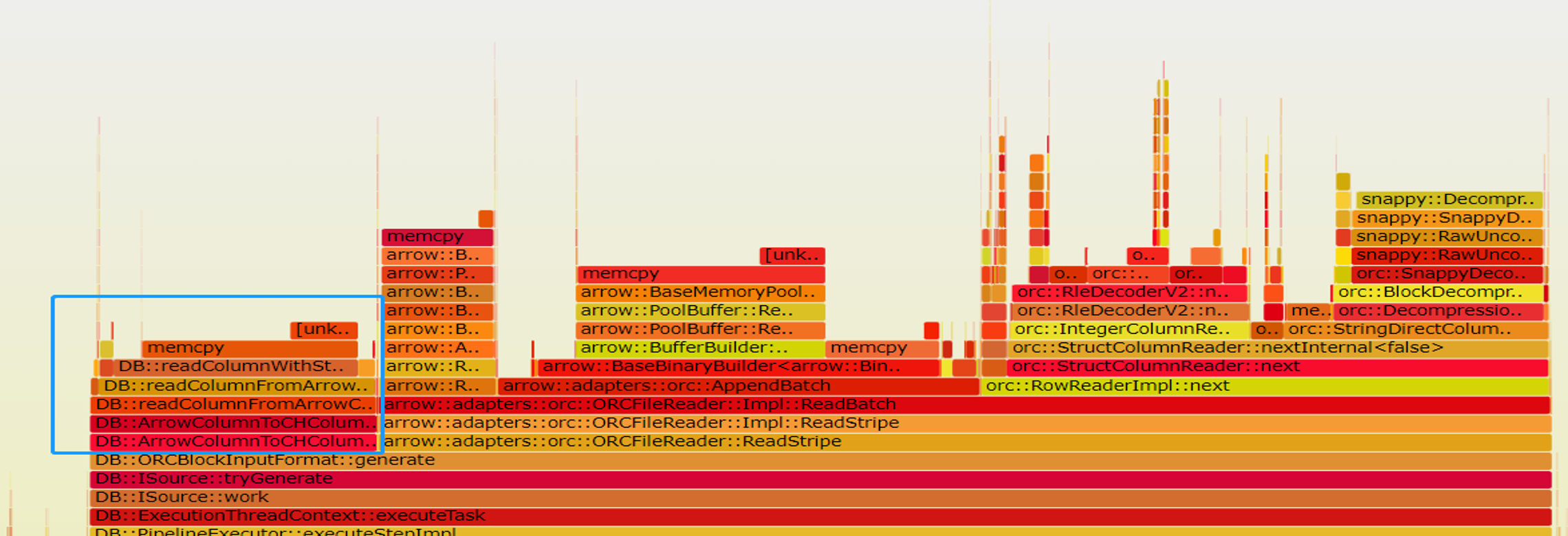
我们在CH#53324基于ORC库实现了Native ORC Reader, 它避免了基于Arrow库的ORC Reader的多次向量转化,直接将ORC向量转化为CH向量,从而大幅提升了ORC读取性能。经过生产数据实测,性能加速1.6x。
CH社区在CH#72105中也实现了Native Parquet Reader, 它同样避免了多次向量转化开销,美中不足的是,它目前还不支持复杂类型的读取功能,也不支持过滤下推功能。Kyligence在CH#70611中实现了新的Native Parquet Reader,支持复杂类型和过滤下推功能,性能相比基于Arrow的Parquet Reader提升50%,不过还在review中,期待早日能合入社区。
列裁剪优化
CH#56122和CH#56117分别实现了ORC和Parquet的嵌套列裁剪优化。那么什么是嵌套列裁剪呢,假设我们有一个ORC文件,包含列
a string,
b int,
c struct<d int, e string>
在列式存储中,每一列都被单独存储。一般的列裁剪只会裁剪掉不需要的列,比如在查询中只使用了列a和c.e,那么一般的列裁剪只会裁剪掉b列,保留a和c。而嵌套列裁剪则会进一步分析嵌套结构,只保留必要的嵌套字段,比如在这个例子中,嵌套列裁剪会进一步裁剪掉c.d列,只保留c.e。因此嵌套列裁剪相比一般的列裁剪可以进一步减少IO和后续的CPU计算。在CH perf tests中,ORC嵌套列裁剪提速2.2x, Parquet嵌套列裁剪提速1.8x。
CH#62210针对JSON格式实现了某种意义上的列裁剪,虽然JSON并非列式存储:在解析列式JSON的每一行时,CH会判断是否已经读取了所有需要的列,如果是,则跳过剩余的列解析,从而减少IO和后续CPU计算。在CH perf tests中,JSON读取提速1.5x。
过滤下推
过滤下推是指在读取数据时,尽可能地将过滤条件下推到数据源层,从而减少读取的数据量。Gluten + CH Backend中已经支持了ORC和Parquet的过滤下推。
我们在CH#56122中实现了ORC Native Reader的过滤下推功能,它通过将Filter算子中的过滤条件下推到Native ORC Reader中,而Native ORC Reader将过滤条件转化为SearchArgument。在读取ORC文件时,Native ORC Reader会根据SearchArgument匹配file/stripe/rowgroup等层级的minmax统计信息和布隆过滤器,如果发现二者并无交集,则跳过当前层级的读取,从而减少IO和后续CPU计算。在ORC数据经过排序的前提下,范围查询提速8.7x, 点查提速117x。
而CH社区在CH#52951中基于Parquet Reader实现了file/rowgroup层级的过滤下推功能,但是无法下推到page层级。在CH perf tests中,Parquet过滤下推提速7.4x。而Kyligence在CH#70611中实现了Native Parquet Reader的过滤下推功能,它支持page层级的过滤下推,并且支持复杂类型的过滤下推.
我们在Gluten#3301中集成了CH的ORC和Parquet过滤下推功能。但是需要注意的是,过滤下推需要配合列式存储的排序才能发挥最大效果。否则额外读取minmax统计信息和可能的布隆过滤器的开销可能会超过其带来的性能提升。
不管是ORC还是Parquet的过滤下推,其原理都是类似的:都是通过列式存储中不同层级的统计信息和可能的布隆过滤器来判断是否需要读取当前层级的数据。
异步IO优化
首先要明确一个背景,在我们生产环境的使用场景中,每个Spark Task只会被分配一个core。由于这一约束,我们的异步IO模型得以简化,一个主线程负责发起IO请求,并在数据在内存中就绪后进行后续的计算(decompress + decode等), 若干后台线程组成IO线程池,负责处理IO请求,主线程和后台线程之间通过任务队列进行通信。也就说,我们的优化方案中主线程中计算操作的并行度始终为1。
我们在ORC#2048中支持了ORC的异步IO接口preBuffer,允许提前通过该接口预读ORC文件某些stripes中的某些列,并将结果缓存到内存中。这样在实际读取时,就可以直接从内存中获取数据,而不需要从远程IO中读取,从而将远程IO延迟隐藏在其他计算中。
在preBuffer的实现中,我们会根据metadata计算stripes中要读取的列的偏移量和长度,形成IO ranges, 然后合并相邻的IO ranges,此举是为了减少IO请求次数,然后将这些IO ranges提交给异步IO线程池进行预读。而在实际读取数据时,则先等待后台的预读任务完成,然后直接从内存中获取数据。
我们在CH#70534中应用了ORC的异步IO接口preBuffer,在读取当前ORC Stripe的数据时,首先Prefetch下一个Stripe的数据,将下一个Stripe的IO隐藏在当前Stripe的计算中,从而减少IO延迟。经过生产环境的测试, ORC Scan性能加速比1.45x。
Kyligence在CH中实现了Parquet Reader的异步IO Prefetch功能,实现原理和ORC相似,在此不再赘述。以下是Intel Vtune采集的w/wo prefetch的多线程CPU利用率对比


可以看到,没有异步prefetch时,由于同步IO的延迟,CPU利用率较低,而有了异步prefetch后,CPU基本能打满。
除了ORC和Parquet之外,我们在Gluten#7598中实现了Text文件的异步IO预读功能:它将相邻的file segments读取请求通过任务队列提交给异步IO线程池进行预读,然后在实际读取从内存中获取。经过测试,Text文件的异步IO预读性能加速1.6x。
同步IO


异步IO预取。


分区读优化
我们Gluten中早就实现了ORC和Parquet的分区读优化,ORC和Parquet分区读的的最小粒度是ORC Stripe和Parquet RowGroup,通过分区读优化,可以提高Stage中Scan算子的并行度。
对于Text格式,我们在Gluten#1584中实现了不带压缩的Text格式的分区读。我们都知道,Text格式一般是按行分割记录的,但是Spark传递给Native Engine中的file split却不一定和行对齐,所以需要在运行时调整file split的起始位置和结束位置,使其对齐到行边界。
Spark中一般使用bzip2对Text格式文件进行压缩,因为bzip2是唯一支持分区读的压缩格式。bzip2压缩文件由一个个compression block组成,每个block之间通过block delimeter分割。注意,spark传递给CH中的file split并非是按照block对齐的,而每个block解压后的数据并非是按照行对齐的,这就需要我们设计专门的对齐算法,使得所有分区读的内容和串行读的内容一致。我们在Gluten#7638中实现了bzip2的分区读优化,生产环境测试显示,分区读相比读取整个文件对查询的加速比为1.5x。
编码优化
我们在CH#69481中实现了ORC读取时dict-encoding字段到CH LowCardinality(String/FixedString)列的转化,在优化之前,ORC dict-encoding字段被直接转化为CH中的String列,这会导致额外的内存消耗和CPU计算开销。经过优化后,ORC dict-encoding字段被转化为CH中的LowCardinality(String/FixedString)列,从而减少了内存消耗和CPU计算开销。经过测试加速比达2.6x。
在相反的方向上,我们在Gluten#68591中实现了ORC写入时CH LowCardinality(String/FixedString)列到ORC dict-encoding字段的转化,这有利于减少ORC文件的大小,而ORC文件大小的减少又有利于后续远程IO读取的性能提升。在我们的测试中,ORC文件大小减少了34%,而后续的ORC文件读取性能加速2.3x。
在开发CH LowCardinality列和ORC dict-encoding列互转的过程中,我们发现ORC库中dict-encoding字段的写入性能远远小于flat-encoding字段,经过性能分析发现瓶颈在于字典编码的实现中使用了std::map, 而随着数据的写入,std:🗺:insert成为瓶颈。我们在ORC#2010将std::map替换为std::unordered_map,从而提升了字典编码的写入性能。经过测试,字典编码字段的写入性能加速比1.97x。
计划优化
Common Subexpression Elimination优化
前面我们提到,Vanilla Spark中的CSE只在Runtime中进行,因为无法为Gluten所用。为了解决这个问题,我们在Gluten#4016中引入了Gluten的CSE优化规则,它基于Spark逻辑计划,消除window/aggregate/project/sort等算子中的重复表达式,具体实现方式为:递归解析以上算子中的子表达式,如果发现某个子表达式出现了两次或以上,则在当前算子前置一个Project算子,将该子表达式的计算结果存储在一个新的临时列中,然后在当前算子中使用这个临时列代替原来的子表达式。这样就可以避免重复计算,提升查询性能。经生产环境验证,CSE优化在某些case下加速比1.9x。
但是我们发现,虽然上面的优化消除了Spark计划到Substrait计划中的重复表达式,但是在Substrait计划到CH计划的转换过程中,可能会引入新的重复表达式。因此我们在Gluten#8284中基于CH ActionsDAG实现了CSE优化,实现了对Substrait解析阶段的兜底。
Nested Column Pruning优化
在复杂情况下,Spark自带的Nested Column Pruning优化可能无法正确地裁剪掉不需要的嵌套列。我们在Gluten#7869和Gluten#7992中同样基于逻辑计划扩展了Nested Column Pruning优化规则,使得其对复杂条件下的Generate和下游算子也能正确地裁剪掉不需要的嵌套列。经测试,性能提升几倍到十几倍不等。
SELECT
abflag,
event.event_info,
event.log_extra,
FROM
test_table
LATERAL VIEW EXPLODE(events) t0 AS event
LATERAL VIEW EXPLODE(split(event.log_extra [ 'abflags_v3' ], ',')) AS abflag
WHERE
event.event_id = 'xx'
AND event.log_extra [ 'scene' ] = 'xxx' -- popular页
AND event.event_info [ 'dispatch_id' ] IS NOT NULL
AND event.event_info [ 'dispatch_id' ] != ''
AND deviceid != 'xx'
AND abflag IN ('xx', 'xx')
order by uid limit 100;
CHNativeColumnarToRow (10)
+- ^ ProjectExecTransformer (8)
+- ^ FilterExecTransformer (7)
+- ^ GenerateExecTransformer (6)
+- ^ FilterExecTransformer (5)
+- ^ GenerateExecTransformer (4)
+- ^ ProjectExecTransformer (3)
+- ^ FilterExecTransformer (2)
+- ^ NativeScan parquet (1)
SELECT * FROM (
SELECT
game_name,
CASE WHEN
event.event_info['tab_type'] IN (5) THEN '1' ELSE '0' END AS entrance
FROM aj
LATERAL VIEW explode(split(country, ', ')) game_name AS game_name
WHERE event.event_info['action'] IN (13)
) WHERE game_name = 'xxx';
CHNativeColumnarToRow (8)
+- ^ ProjectExecTransformer (6)
+- ^ FilterExecTransformer (5)
+- ^ CHGenerateExecTransformer (4)
+- ^ ProjectExecTransformer (3)
+- ^ FilterExecTransformer (2)
+- ^ ScanTransformer orc default.aj (1)
Join优化
我们知道在CH中,Hash Join的性能和Join的顺序有很大关系。通常建议右表小于左表,因为右表用于构建hash table, 如果右表过大,则会导致hash table过大,造成频繁的cache miss,影响join性能。我们在Gluten#6770中根据Spark AQE中的统计信息,判断join children的大小,如果右表行数远远大于左表,则将左右表顺序进行交换,从而提升CH中Hash Join执行的性能。
Aggregate优化
Spark中的grouping sets语句底层对应的是expand算子。在优化前,grouping sets对应的CH计划:
expand -> aggregate phase1 -> shuffle -> aggregate phase2
其中expand算子会将一行输入根据grouping sets进行扩展,生成多行输出。expand算子会生成大量的中间行,导致后续的aggregate phase1的的计算开销非常大。
我们针对这种情况进行了优化, 优化后的CH计划为:
aggregate phase1 -> advanced expand -> shuffle -> aggregate phase2
当聚合键的基数较小时,我们将expand算子推迟到aggregate phase1之后,这样避免了expand算子生成大量中间行,聚合键的基数越小, 优化效果更佳明显,
disable lazy expand: expand耗时27.4s, 处理行数1.9亿,aggregate phase1耗时7.5min,处理行数30亿。

enable lazy expand: expand耗时87ms, 处理行数64w, aggregate phase1耗时33.8s,处理行数1.9亿。

我们看到,优化之后无论是expand还是aggregate算子,其处理行数和耗时都大大减小。
Expression Rewrite优化
Expression Rewrite优化是指在保证语义相同的情况下,将某些表达式重写为更高效的表达式,从而提升查询性能。我们针对生产环境高频的表达式进行了一系列重写优化。
Gluten#9185中,我们实现了以下转化规则
sum(if(cond, expr, 0))->sum(expr) FILTER (WHERE cond)func(if(cond, expr, null))->func(expr) FILTER (WHERE cond)带FILTER CLAUSE的聚合函数在CH中会被转化为带if-combinator的聚合函数,这样可以减少中间结果生成,从而提升查询性能。经过测试,该优化对count/sum/avg等常见聚合函数又8%到13%的性能提升。
Gluten#9198中,我们实现了以下优化规则
- Rule 1: sum(expr / literal) -> sum(expr) / literal
- Rule 2: sum(expr * literal) -> literal * sum(expr)
- Rule 3: sum(literal * expr) -> literal * sum(expr) 根据乘法和除法的结合律和分配律,我们可以将乘法和除法提到聚合函数外部,从而减少乘法和除法的计算开销:每个乘法和除法只计算一次,而不是每行都计算一次。经测试,该优化有15%的性能提升。
Gluten#8874中将子字符串比较转化为字符串切片比较: substr(s, 1, 3) = 'abc' -> compareSubstrings(s, 'abc', 0, 0, 3)。其中compareSubstrings实现了一个字符串切片对另一个字符串的比较,避免了substr函数生成中间结果的开销,经测试,性能提升2.4x。
Gluten#4617和Gluten#3592通过将时间戳字符串比较转化为时间戳比较,提升了表达式的执行性能: from_unixtime(ts, 'yyyy-DD-mm') = '2025-01-01' -> ts > to_unix_timestamp('2025-01-01', 'yyyy-DD-mm')。可以看到,优化之后,计算过程中不再生成字符串中间结果,也不基于字符串执行比较,所有的计算基于时间戳(在CH中底层用整数表示)。经过测试,性能提升2.35x
Gluten#3111发现生产用户频繁使用get_json_object(str, xx)对同一个json string抽取不同的key,
为了复用中间结果,将get_json_object(str, field1)和get_json_object(str, field2)改写成flattenJSONStringOnRequired(str, field1|field2).field1和flattenJSONStringOnRequired(str, field1|field2).field2, 当具有相同str参数的get_json_object(str, field)表达式重复7次时,加速比1.59x
Gluten#8517将嵌套的spark and/or表达式在CH解析阶段进行扁平化处理,比如将and(a, and(b, c))转化为and(a, b, c, d),既减少了中间向量的生成,经过测试,性能提升1.7x。
Gluten#4030和Gluten#4042中对CH计划解析进行了优化,在spark条件分支表达式中如果分支数不超过2,则将其转化为CH if函数,而不是multiIf函数。这是因为后者为了支持多分支的通用性牺牲了一些性能。经测试,加速比1.7x。
复用CH plan optimization
CH自带的plan optimization是作用于CH逻辑计划的,因此它可被Gluten复用,只需要开启相应的开关--conf spark.gluten.sql.columnar.backend.ch.runtime_settings.query_plan_enable_optimizations=true。其中包含了很多优化规则,如相邻project/filter算子合并、array join算子上提、limit下推、filter下推等等。对Gluten来说,CH自带的Plan optimization是免费的午餐,不吃白不吃。
计算优化
替换更高效的算法或库
我们发现,最新版clang编译器在x86_64上支持了256位整数及其算数运算,根据我们的微基准测试。其性能显著高于CH中原有的int256实现。因此我们在CH#73658中使用clang自带的int256实现,替换了CH中原有的int256实现。由于Gluten中decimal类型底层依赖CH的int256实现,我们在Gluten#8105中对Gluten中的sparkDecimal*函数应用了上面的优化,结合一些必要的重构,在生产查询上获得了6%的性能收益。
CH#77789调整了sort算子归并排序的算法:在优化前,确定要输出的batch size时,首先会在begin_cursor进行线性探测,从当前行一直向后遍历,并进行sort key columns的比较,直到当前行不小于next_child_cursor的当前行。这个过程性能不佳,每次遍历一行都对应着一次比较,而一次比较可能对应着多次IColumn::compareAt虚函数调用。而对于小基数列,因为每个cursor中数据相对集中,因此可通过二分搜索来确定batch size, 从而减少比较次数。最后,为了避免大基数列场景下可能的性能回退,最终确定了自适应的batch size计算算法,即首先线性探测最多16次,如果尚未找到临界点,则切换到二分搜索在剩余行中继续查找。在CH perf tests中,性能提升1.2-1.9x
CH#61632对UTF8相关的字符串函数(substringUTF8/reverseUTF8/lowerUTF8/upperUTF8等)进行了优化,实现了自适应算法:对于一个输入字符串向量,首先通过SIMD指令判断其中是否包含非ASCII字符,如果没有,则按照ASCII字符的方式向量化的处理字符串;如果有,则使用UTF8字符的方式处理字符串。而在现实世界中,大部分字符串都是ASCII字符,因此这种自适应算法可以大幅提升性能。经测试,性能提升1.07-1.62x。
我们在CH#36415中实现了Parallel Hash Join算法,它是CH中Hash Join的一个多线程版本,build side可并行hash table, probe side也是并行的,每个线程内对输入Block行scatter,得到多个分区的Block,再为每个分区的Block执行probe, 最终将每个分区的join结果合并。并行度为2、4、8、16时,性能提升分别为1.5x、2.8x、4.5x、5.8x。
后来CH社区基于parallel hash join进一步进行了优化, 优化后build side每个线程并行构建two level hash table的的部分bucket, 在build结束之后将每个线程构建的结果进行零代价的合并,得到全局的two level hash table。得益于此,probe side无需进行scatter, 这避免了probe side分区和合并的巨大开销。
类型特化优化
类型特化优化是CH中最常见的一种优化方式,通过对列类型提前进行判断,然后调用特化的函数对特定类型的向量进行处理,从而减少运行时调用IColumn中函数的开销。
Gluten#8844针对arraySortSpark函数的实现进行了类型特化优化,通过类型特化去除了non-nullable column和nullable column中compareAt的虚函数调用开销,从而提升了arraySortSpark函数的性能。经测试,性能提升1.1-1.5x。
Gluten#128在实现C2R和R2C转化时,也进行了类型特化优化:在ClickHouse向量和Spark行互转时,针对不同的CH向量类型进行了特化处理,避免了Field中间结果造成的巨大开销。优化后,C2R性能提升1.3, R2C性能提升1.2x。
同类型优化还有
devirtualize优化
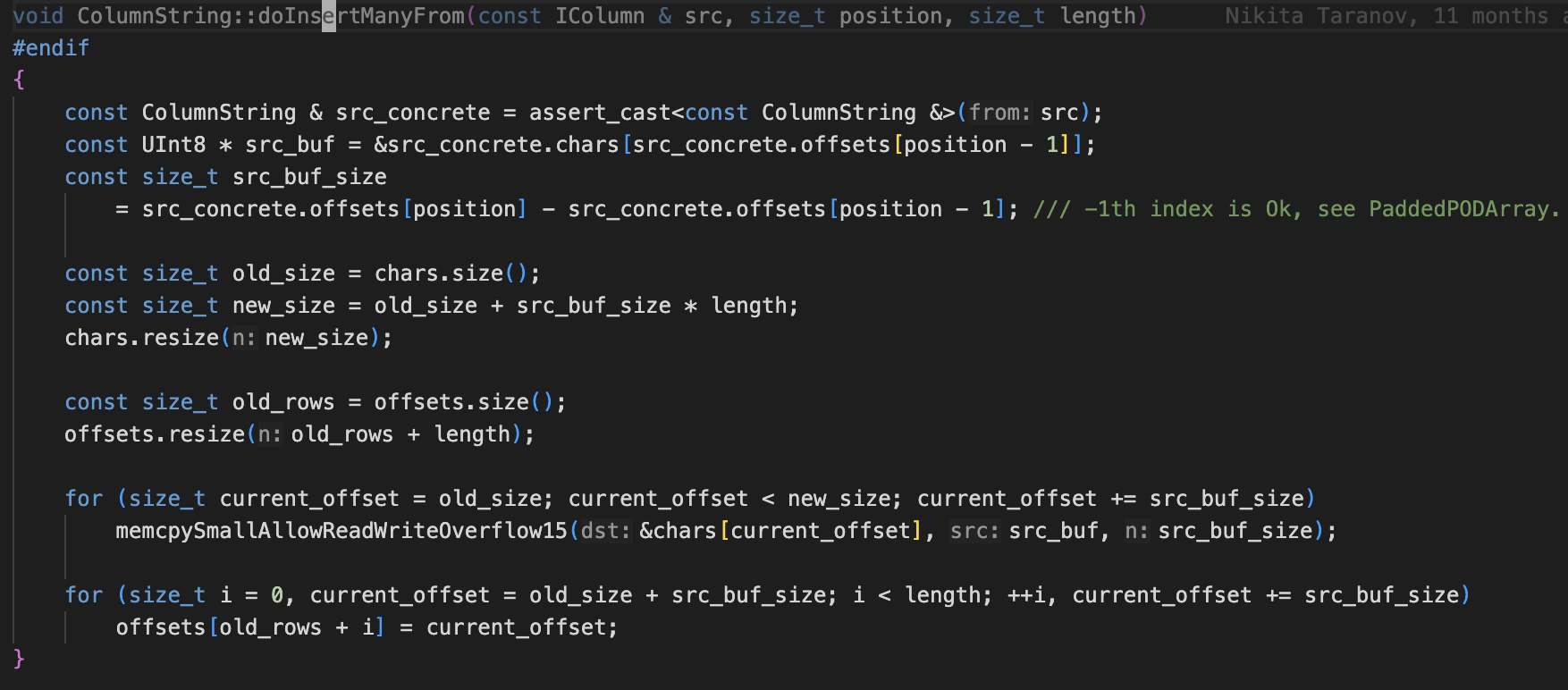
CH#60846针对nullable/string/array向量的insertManyFrom接口进行了devirtualize优化,在CH中insertManyFrom是虚函数,用于将其他向量中某一行重复追加到当前向量。在优化前,对nullable/string/array向量,其实现如下
virtual void insertManyFrom(const IColumn & src, size_t position, size_t length)
{
for (size_t i = 0; i < length; ++i)
insertFrom(src, position);
}
可以看到其中频繁调用虚函数insertFrom。我们在nullable/string/array向量中override了insertManyFrom函数,去掉了虚函数调用开销。经测试,该接口性能提升了数十倍。
CH#63677中实现了all join中右表column构建的优化:在probe阶段,首先收集左表中每一行对应的RowRefList, 最后在生成join结果时,遍历所有RowRefList, 将对应的记录append到join结果的右表字段中。通过将分散的insertFrom调用集中到一块执行,提高了虚函数的执行效率。经测试,性能提升1.5x。社区后又在CH#77350中对all join中右表column构建进行了进一步的优化:在IColumn中新增批量执行接口fillFromRowRefs和fillFromBlocksAndRowNumbers替代循环中频繁执行insertFrom,通过CRTP的方式彻底去掉了右表column构建中虚函数调用开销。CH perf tests中相关case性能提升1.25-1.7x。
CH#60341对all join的hash join算法实现中,右表column构建进行了进一步优化:在build side完成后,当key对应的平均右表行数介于[40, 10000]时,对hash table中的所有RowRefList进行重整,将其中的行引用从分散的blocks中转移到新创建的block中,保证每个key对应的RowRefList都处在一个连续的行范围内,继而提升probe阶段构建右表column的性能。因为一旦RowRefLists中多行处于一个Block中的连续范围内,构建右表column时可直接使用insertRangeFrom批量接口替代insertFrom虚函数调用,从而使得虚函数调用次数减少一个数量级。而CH#72237则将这种优化推广到grace hash join算法实现中。CH perf tests中相关case性能提升1.6x.
其他同类型优化:
短路优化
- 函数null短路执行
在CH中,大部分函数中如果输入参数中包含null值,则函数的返回值也为null。其内部实现:对于nullable类型输入参数,CH会首先会剥离nullmap, 然后对非null的值进行计算,最后将输入参数中的nullmap重新合并到结果中。试想以下,如果某个输入参数每一行都是null值,CH还是会每一行执行计算,而这些计算是完全没有必要的。因此我们在CH#73820中针对这类函数实现了短路优化:当输入参数中null值超过一定阈值如99%时,只针对不包含null值的行进行计算,从而减少函数的计算开销
- 其他
CH#45244中增加了对col like '%%'、col like '%'、col not like '%'、col not like '%'和match(col, '.*')的fastpath支持,这些表达式在CH中会被转化为常量true或false,从而避免了不必要的计算。经测试性能提升1.29-18x。
CH#45382增加了position函数的fastpath支持:当输入参数是空字符串时,position函数提前返回结果,避免了不必要的计算。经测试性能提升1.9-2.9x。
CH#73965则继续优化了and/or的短路执行逻辑,由于and/or满足交换律,当进行短路执行时,如果对已经物化的non-function column不断进行filter/expand, 代价会非常高。因此本优化首先收集and/or输入参数中的non-function columns, 计算partial result, 然后再将partial result作为新参数参与and/or的短路执行。这个优化减少了filter/expand的调用次数,减少了不必要的计算开销。CH perf tests中相关case性能提升1.5-2.0x。
分配内存优化
提前分配足够多内存
CH#49816中针对grace hash join算子进行了优化:当一个bucket完成hash table的构建后,CH会根据它的带下提前分配下一个bucket的内存,避免下一个bucket对应的hash table不断resize导致的庞大开销。经测试,性能提升1.3x。
其他同类型优化:
减少内存分配
CH#49585对hash join中used flags的内存分配进行了优化:在disjoint只有一个的情况下,hash join的build side每次addBlockToJoin时会执行UsedFlags::reinit(size), 保证在probe side开始前为其分配足够的内存。reinit每次都会重新分配一个std::vector对象,本优化在其中加了个判断,只有当请求大小大于当前std::vector大小时,才创建新std::vector,避免频繁的内存分配和释放。经测试,FULL/RIGHT JOIN性能提升2x.
其他同类型优化:
向量化优化
自动向量化
我们在CH#45296中对multiIf函数进行了向量化优化。在优化前,multiIf函数是按行执行的,遍历每一行,在每一行内遍历所有分支条件,直到找到值为true的分支,然后将该分支的值追加到结果列中,该实现中循环过于复杂,既有多层循环,又有分支,又有虚函数调用,无法被自动向量化,导致性能很慢。而在优化后,我们判断输入参数类型是否为整数类型,如果是,则列式地执行multiIf函数:首先计算每一行满足条件的分支索引。然后遍历每行的分支索引,将对应的分支值赋值到结果列的底层数组中。通过列式执行和branchless优化,multiIf的执行得以被自动向量化。经测试,性能提升2.3x。CH#57745和CH#60384则进一步扩展了multiIf函数列式执行的支持范围,当输入参数为Nullable(T),且T为数值类型时,也可以被列式执行。
Gluten#8707则通过branchless编程实现了castFloatToInt和sparkDivide函数的自动向量化优化。 以castFloatToInt的实现为例,优化后性能提升2.7x。
优化前

优化后

其他同类型优化:
手动向量化
当编译器无法进行自动向量化优化时,可尝试使用Intel Intrinsics进行手动向量化。
Gluten#4244中使用avx2指令级实现了sparkFloor函数的手动向量化优化,相比优化前加速比1.14。
在ISSUE#61074中,我们发现CH的向量化内存复制实现memcpySmallAllowReadWriteOverflow15Impl被clang编译器优化成了memcpy函数调用,而不是SIMD指令。我们在CH#61075中添加了内存屏障,阻止clang编译器的loop-idiom优化,从而使得手动向量化代码生效。由于memcpySmallAllowReadWriteOverflow15Impl是CH中高频使用函数,该优化加速了15个以上的CH perf tests case,hash join的性能提升1.2x。
inline void memcpySmallAllowReadWriteOverflow15Impl(char * __restrict dst, const char * __restrict src, ssize_t n)
{
__msan_unpoison_overflow_15(src, n);
while (n > 0)
{
_mm_storeu_si128(reinterpret_cast<__m128i *>(dst),
_mm_loadu_si128(reinterpret_cast<const __m128i *>(src)));
dst += 16;
src += 16;
n -= 16;
/// Avoid clang loop-idiom optimization, which transforms _mm_storeu_si128 to built-in memcpy
__asm__ __volatile__("" : : : "memory");
}
}
JIT
JIT是CH中性能优化手段的一个重要补充。我们在CH#73509中为更多常用函数添加了JIT支持,包括abs/modulo/pmod/isNull/comparison functions/logical functions等,同时为Decimal和BigInt类型添加了JIT支持。经测试,在复杂表达式场景下,JIT优化有着不错的收益。该PR目前还在review中,期待早日被社区合入。
总结
本文详细介绍了Gluten + ClickHouse backend在实际生产环境中的多项性能优化案例,涵盖了IO、计划、计算等多个层面。通过Native Reader、列裁剪、过滤下推、异步IO、分区读、编码优化等IO优化手段,大幅提升了数据读取效率。计划优化方面,针对CSE、嵌套列裁剪、Join顺序、聚合、表达式重写等场景进行了深入优化,显著减少了重复计算和中间数据量。计算层面则通过算法替换、类型特化、devirtualize、短路、内存分配、向量化、JIT等手段,充分发挥硬件和底层库的性能潜力。整体来看,这些优化措施在实际业务查询中带来了数倍甚至数十倍的性能提升,为大规模数据分析提供了坚实的技术支撑。未来,随着社区和业务需求的不断演进,性能优化仍将持续深入,助力更高效的数据处理。
参考
https://docs.google.com/spreadsheets/d/12jTNKnqT8dAg3PsCXQvepFfNR9WghUqwH-FTm3NGqGs
文章作者 后端侠
上次更新 2025-06-02