Gluten+CH backend性能优化--工具篇
文章目录
性能优化工具
俗话说,工欲善其事,必先利其器。在做事的过程中,有一个趁手的工具能让码农们事半功倍,在性能优化领域也是如此。上篇我们介绍了Gluten + CH backend性能优化的问题与挑战。
本文将深入剖析Gluten+CH backend优化过程中涉及的全栈工具链,涵盖从基准测试到生产调优的完整生命周期。
Benchmark工具
在进行性能优化的过程中,首先要对感兴趣的部分进行测量,最直观的测量指标就是系统时间。我们要构造合适的Case来突出感兴趣的代码路径,可能是一个查询,也有可能是一段函数。然后保持环境的一致性(硬件、操作系统、工作负载),在指定代码版本下,使用Benchmark工具对其性能进行测量。最后,我们会同时测量优化前版本和优化后版本,并比较他们的性能指标,快慢一目了然,童叟无欺。经过这样的测量和比较,我们才能知道哪个代码版本性能更优,对应的性能优化方法更有效。
CH系统表
numbers和zeros
如果你给CH贡献过Performance Improvement相关的PR, 相信你对numbers(N)和system.zeros(N)不会陌生。前者从内存中产生并返回一个名为number的UInt64列,该列从零开始产生递增的自然数。后者从内存中产生并返回一个名为zero的UInt8列,该列的值为零。
如果你想测量某个查询在CH Server上执行的性能,numbers和zeros将会为你提供极大的便利。它们的优势在于:如果你优化的是一个简单的表达式或者算子,无需提前构造和加载表数据,只需通过指定行数即可快速生成所需规模的数据集。numbers和zeros返回的行数越多,越能考察系统在大数据量下的表现,同时也能更好地暴露潜在的性能瓶颈。通过灵活调整生成的数据量,可以方便地对比不同优化方案在各种负载下的效果。
例如,如果我的目标是优化sum函数对Decimal128输入的有条件聚合,可使用:
select sumIf(number::Decimal128(3), rand32() % 2 = 0) from numbers(100000000) format Null settings max_threads=1;
其中 format Null 避免了将查询结果输出到终端或文件,从而消除了I/O带来的性能干扰,使得测量结果更加专注于计算本身的性能表现。
注意:在 clickhouse-server 中,max_threads 默认等于系统的逻辑核心数,表示查询的最大并发执行线程数。我们建议在对查询进行 Benchmark 时,将 max_threads 显式设置为 1,原因如下:
- 系统环境中可能存在其他负载,将查询限制为单核执行更容易实现资源独占,减少外部干扰。
- ClickHouse Server 的多线程调度本身会引入额外开销,可能影响 Benchmark 结果的准确性。
实际上,如果你查看CH中的perf tests(tests/performance/), 会发现numbers和zeros使用甚广。它几乎是CH中最简单的Benchmark工具。
generateRandom
在某些更复杂的场景下,比如需要构造两张及以上的表,或者对表的数据分布和字段类型有特定要求时,numbers和zeros可能无法完全满足需求。这时,generateRandom就成为了更合适的选择。
generateRandom是CH中的一个table function。generateRandom会根据用户指定的schema输出随机数据。使用它能够生成稍复杂的测试数据,用于测量性能。
语法:
generateRandom(['name TypeName[, name TypeName]...', [, 'random_seed'[, 'max_string_length'[, 'max_array_length']]]])
其中:
- name表示schema中的列名
- TypeName表示schema中的列类型
- random_seed指定随机种子
- max_string_length指定输出的随机字符串的最大长度
- max_array_length指定输出的随机数组的最大长度
例如,
SELECT lower() FROM generateRandom('b String', 1, 10, 2) LIMIT 100000000;
需要注意,generateRandom在生成随机数据时本身会消耗较多资源,其开销在Benchmark测试中不可忽视。为了更准确地评估目标代码的性能,通常建议先使用generateRandom生成数据并导入到CH的Memory表中,再基于该表进行Benchmark测试。这样可以有效避免数据生成过程对性能测量结果的干扰,使测试更加聚焦于被优化的核心逻辑。
CREATE TABLE test_isnotnull
(
a Array(Nullable(Int32))
) ENGINE = Memory;
insert into test_isnotnull select * from generateRandom('a Array(Nullable(Int32))', 1, 19, 2) limit 1000000000;
select isNotNull(a[0]) from test_isnotnull settings max_threads=1;
clickhouse-benchmark
clickhouse-benchmark 是 ClickHouse 提供的命令行工具,可用于持续向 ClickHouse 发送指定查询,并输出详细的基准测试报告。当性能提升幅度较小时(如仅有百分之几),直接在 clickhouse-client 中用 numbers、zeros 或 generateRandom 进行测试,往往难以区分性能波动是由系统环境变化还是代码优化引起的。此时,clickhouse-benchmark 能够提供更稳定、可重复的基准测试结果,有助于准确评估优化效果。
clickhouse-benchmark --concurrency 1 -i 10 --port <port> --password <password> --<settings>=<value> --max_threads=1 --query <query>
其中:
- concurrency参数表示客户端发送的并发度, 建议为1
- i表示查询发送次数,可根据单query查询耗时自行调整
- port和password表示CH server的端口和密码
- query表示带测量的查询
clickhouse-benchmark的summary信息如下, 可得到不同百分位下的查询耗时。
Queries executed: 10.
localhost:9001, queries: 10, QPS: 0.640, RPS: 31611326.292, MiB/s: 2756.318, result RPS: 0.000, result MiB/s: 0.000.
0% 1.441 sec.
10% 1.467 sec.
20% 1.478 sec.
30% 1.483 sec.
40% 1.490 sec.
50% 1.493 sec.
60% 1.493 sec.
70% 1.529 sec.
80% 1.544 sec.
90% 1.553 sec.
95% 1.714 sec.
99% 1.714 sec.
99.9% 1.714 sec.
99.99% 1.714 sec.
google benchmark
google benchmark 是一个高性能的微基准测试框架,广泛用于 C++ 代码的性能评测。在 Gluten + ClickHouse Backend 的开发过程中,我们主要用google-benchmark对底层的关键代码路径进行细粒度的性能测试,从而能够精准量化代码优化所带来的性能收益。
不管是Gluten还是CH代码库中都集成有google benchmark, Gluten中位于cpp-ch/local-engine/tests/benchmark_*.cpp, CH中位于src/**/benchmarks/*.cpp。注意在编译Gluten + CH backend中的google benchmark代码时加上选项-DENABLE_BENCHMARK=1
下面是一段典型的google benchmark输出
./build_gcc/utils/extern-local-engine/tests/benchmark_local_engine --benchmark_filter="(Addition|Subtraction|Multiplication|Division)<Old.*>"
Running ./build_gcc/utils/extern-local-engine/tests/benchmark_local_engine
Run on (32 X 2100 MHz CPU s)
CPU Caches:
L1 Data 32 KiB (x16)
L1 Instruction 32 KiB (x16)
L2 Unified 1024 KiB (x16)
L3 Unified 11264 KiB (x2)
Load Average: 4.79, 5.12, 5.49
------------------------------------------------------------------------
Benchmark Time CPU Iterations
------------------------------------------------------------------------
BM_Addition<NewInt128> 1.43 ns 1.43 ns 488198747
BM_Subtraction<NewInt128> 1.51 ns 1.51 ns 486720421
BM_Multiplication<NewInt128> 1.52 ns 1.52 ns 450071487
BM_Division<NewInt128> 1.48 ns 1.48 ns 471973890
BM_Addition<NewUInt128> 1.46 ns 1.46 ns 480687874
BM_Subtraction<NewUInt128> 1.46 ns 1.46 ns 488204076
BM_Multiplication<NewUInt128> 1.45 ns 1.45 ns 468576127
BM_Division<NewUInt128> 1.48 ns 1.48 ns 477379447
BM_Addition<NewInt256> 2.49 ns 2.48 ns 291377319
BM_Subtraction<NewInt256> 2.52 ns 2.52 ns 284595240
BM_Multiplication<NewInt256> 2.48 ns 2.48 ns 276363723
BM_Division<NewInt256> 2.44 ns 2.44 ns 286877215
BM_Addition<NewUInt256> 2.53 ns 2.53 ns 266497385
BM_Subtraction<NewUInt256> 2.48 ns 2.48 ns 287899525
BM_Multiplication<NewUInt256> 2.45 ns 2.45 ns 287882140
BM_Division<NewUInt256> 2.47 ns 2.47 ns 288479037
其他
TPC-H和TPC-DS
TPC-H和TPC-DS是两种广泛用于评估数据库系统决策支持能力的基准测试。TPC-H包含8张表,22个查询,面向传统数仓,侧重单表复杂聚合。TPC-DS包含7张事实表,17张维度表,贴近现代大数据分析,更接近真实生产环境。Apache Gluten结合这两种基准测试,验证其在复杂OLAP场景下的加速效果。TPC-H和TPC-DS在业界有着广泛的认可度,Gluten + CH Backend在支持TPC-H和TPC-DS中所有功能点之后,也基于这两个基准测试进行了多轮性能优化。
ClickBench
ClickBench是CH社区发起的开源Benchmark项目,代表了点击流、流量分析、Web分析、结构化日志、事件打点等典型工作负载。各大数仓(Umbra、DuckDB、StarRocks、Doris)在ClickBench中同台竞技,你追我赶。在官方网站上可查看不同数仓系统在不同硬件下的性能表现。
Benchmark工具总结
| 工具/方案 | 适用场景 | 使用方式/特点 |
|---|---|---|
| CH系统表(numbers/zeros) | 简单算子、表达式性能测试,快速生成大规模数据 | 直接在clickhouse-client中调用,如SELECT ... FROM numbers(N),无需准备表数据,适合算子/表达式微基准测试 |
| generateRandom | 需要复杂schema或多表、特定数据分布的测试 | 通过table function生成随机数据,可先导入Memory表再测试,适合复杂查询或多表场景 |
| clickhouse-benchmark | 查询性能微小变化、需要多次重复测试 | 命令行工具,支持并发和多次迭代,输出详细统计信息,适合对比优化前后性能,排除偶然波动 |
| google benchmark | C++底层代码路径、函数级微基准测试 | 代码内嵌测试用例,编译运行后输出每个case的耗时,适合定量分析底层实现的性能差异 |
| TPC-H/TPC-DS | 评估系统整体OLAP能力、复杂SQL场景 | 标准化测试集,包含多表/复杂查询,适合系统级性能对比和优化 |
| ClickBench | 真实工作负载、业界对比 | 社区维护的公开benchmark,涵盖多种典型分析场景,适合横向对比不同系统 |
CPU调优工具
什么是CPU调优呢?我的理解是,通过对被观测的计算密集型任务进行采样打点,找到其中的热点代码及其CPU占比,通过各种手段优化代码实现,从而提升程序的整体性能。说到CPU调优就离不开最常用的火焰图,火焰图被Brendan Gregg发明,是一种可视化性能分析数据的工具,能够直观展示程序在运行过程中各个函数调用栈的CPU消耗情况。通过火焰图,我们可以快速定位热点代码、识别性能瓶颈,从而有针对性地进行优化。
火焰图的横轴表示所有采样的调用栈,宽度代表该调用栈被采样到的次数(即CPU时间占比),纵轴则表示调用栈的深度。每一层的方块代表一个函数,方块越宽,说明该函数消耗的CPU时间越多。通过分析火焰图,可以清晰地看到哪些函数最耗时,以及它们的调用关系。下面是一个典型的火焰图

以下将介绍常用的CPU调优工具,以及使用它们是如何生成火焰图的。
clickhouse-flamegraph
clickhouse-flamegraph是一个命令行工具,它能够将CH系统表中system.trace_log的性能指标以query_id为粒度可视化,形成火焰图。使用方法和优缺点可参考:clickhouse与火焰图
注意,clickhouse-flamegraph依赖运行时产生system.trace_log日志,当采样频率较高时,这个开销很重,拖慢query运行性能,导致火焰图不准确。
Linux Perf
perf是内置于linux kernel中的profiling工具,它能监测各种硬件和软件事件,被广泛用于性能瓶颈的查找和热点代码的定位。正因为他是内置的profiling工具,perf能够避免clickhouse-flamegraph的的上述缺点。perf的缺省采样频率是4000/s, 使用perf也不会导致被观测进程产生明显的性能衰减。
如何使用perf为CH或Gluten生成cpu time或real time的火焰图可参考clickhouse与火焰图。以下将介绍perf常用的一些子命令
- perf stat
perf stat用于查看程序运行过程中一些常见的计数指标,如instructions, cycles, branches, branche-misses, cache-misses等。perf stat的最大作用在于对程序的运行形成一个全局的概览。
perf stat -d -- <command>
perf stat -d -p <pid>
perf stat的输出样例
Performance counter stats for './build_gcc/src/Common/benchmarks/radix_sort':
1,069.32 msec task-clock # 0.549 CPUs utilized
626 context-switches # 585.417 /sec
20 cpu-migrations # 18.703 /sec
4,028 page-faults # 3.767 K/sec
2,216,778,699 cycles # 2.073 GHz (27.91%)
6,189,885,513 instructions # 2.79 insn per cycle (33.03%)
639,225,705 branches # 597.786 M/sec (33.12%)
72,412 branch-misses # 0.01% of all branches (33.38%)
1,460,021,926 L1-dcache-loads # 1.365 G/sec (33.64%)
149,939,709 L1-dcache-load-misses # 10.27% of all L1-dcache accesses (33.80%)
861,549 LLC-loads # 805.696 K/sec (27.60%)
126,798 LLC-load-misses # 14.72% of all LL-cache accesses (26.79%)
1.948737071 seconds time elapsed
1.032000000 seconds user
0.040000000 seconds sys
可以看到,程序执行过程中,CPU利用率为0.549, page-faults为3767次/秒,branch-miss率为0.01%, LLC-load-misses率为14.72%。因此可以大致推断该程序的瓶颈在于memory分配和访问。
- perf top
perf top用于在系统中动态展示CPU占用最多的函数或程序。
# 默认按照cpu time倒序排列
perf top
# 指定某个进程
perf top -p <pid>
# 按照cache-misses次数倒序排列
perf top -e cache-misses
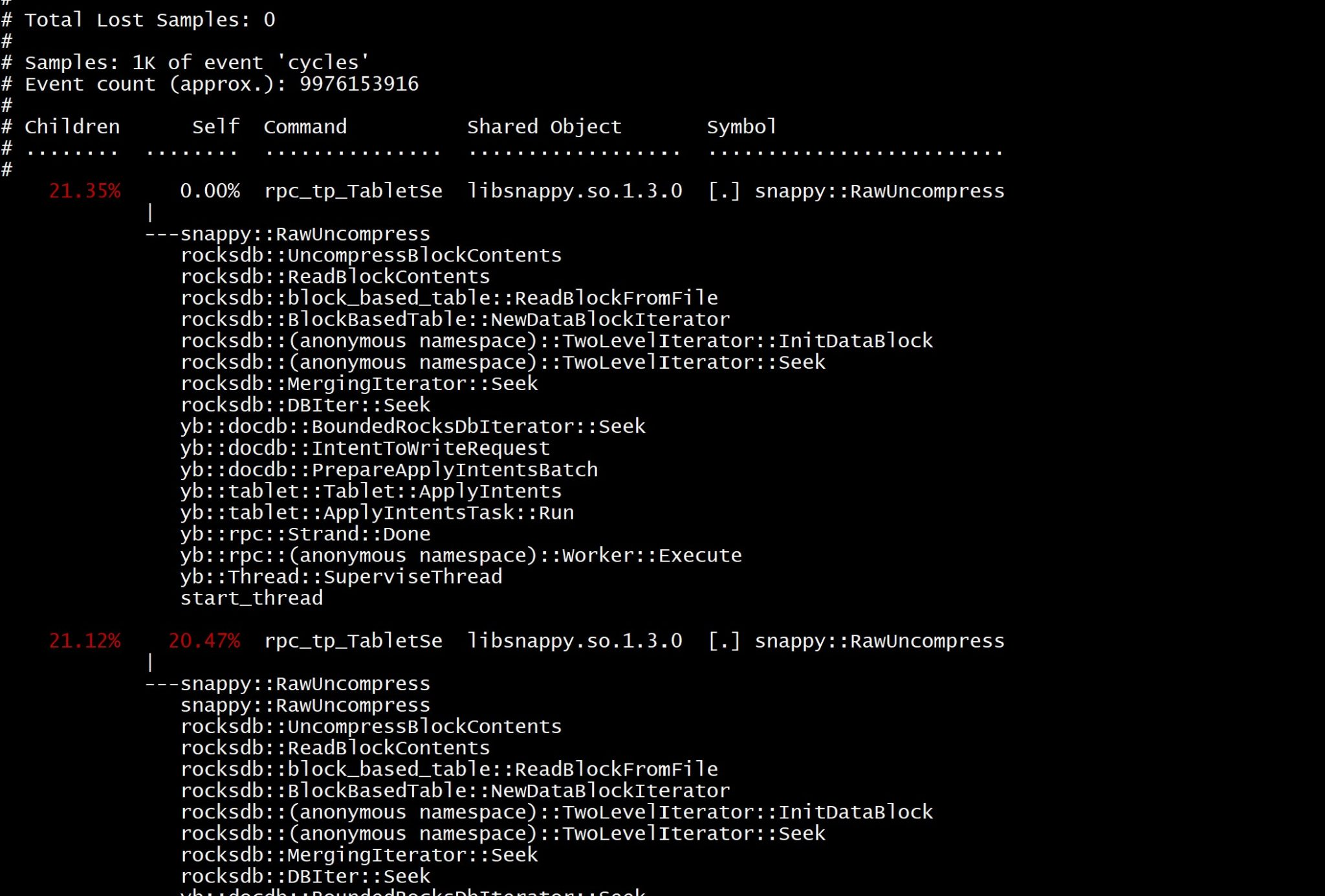
- perf record和perf report
perf record用于统计程序运行过程中的指定事件采样,会在本地生成数据文件。接着运行perf report时会加载本地数据文件,生成一个可视化的页面。如:
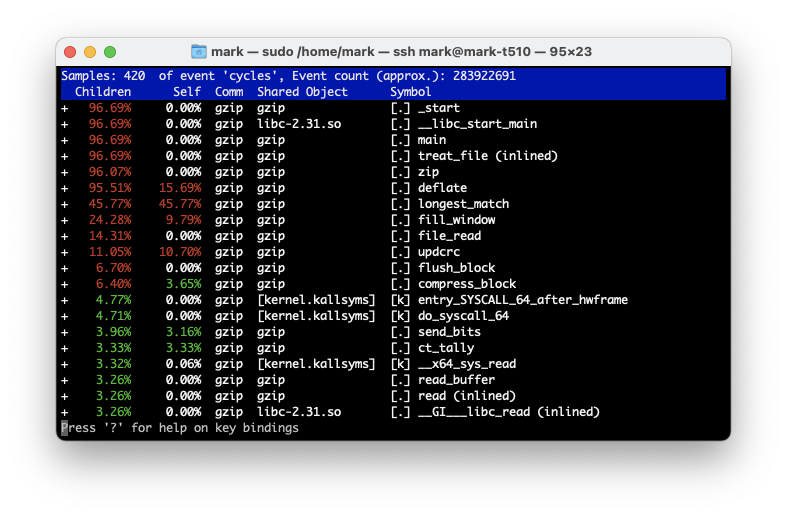
详情见 clickhouse与火焰图
- perf annotate
perf annotate的作用在于对关键路径代码进行代码级分析,精确到每一条汇编指令。
在perf report或perf top页面中,如果在选中symbol上按'a’, 会显示对应的源代码和汇编代码。
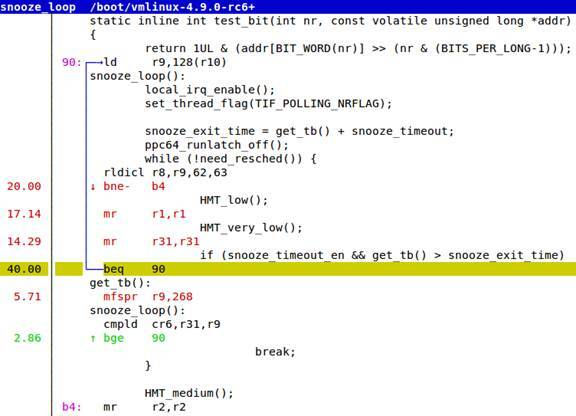
当然也可以在perf record之后,在命令行执行
perf annotate <symbol>
perf annotate --demangle -s <symbol> -M intel
Intel Vtune
在x86平台上,Intel Vtune是比Linux Perf更为强大的性能调优工具,使用它快速发现和分析应用程序及整个系统的性能瓶颈。安装可参考:无GUI的Linux Server配置vtune-gui教程
以下列举CPU调优过程中常用的Intel Vtune子功能
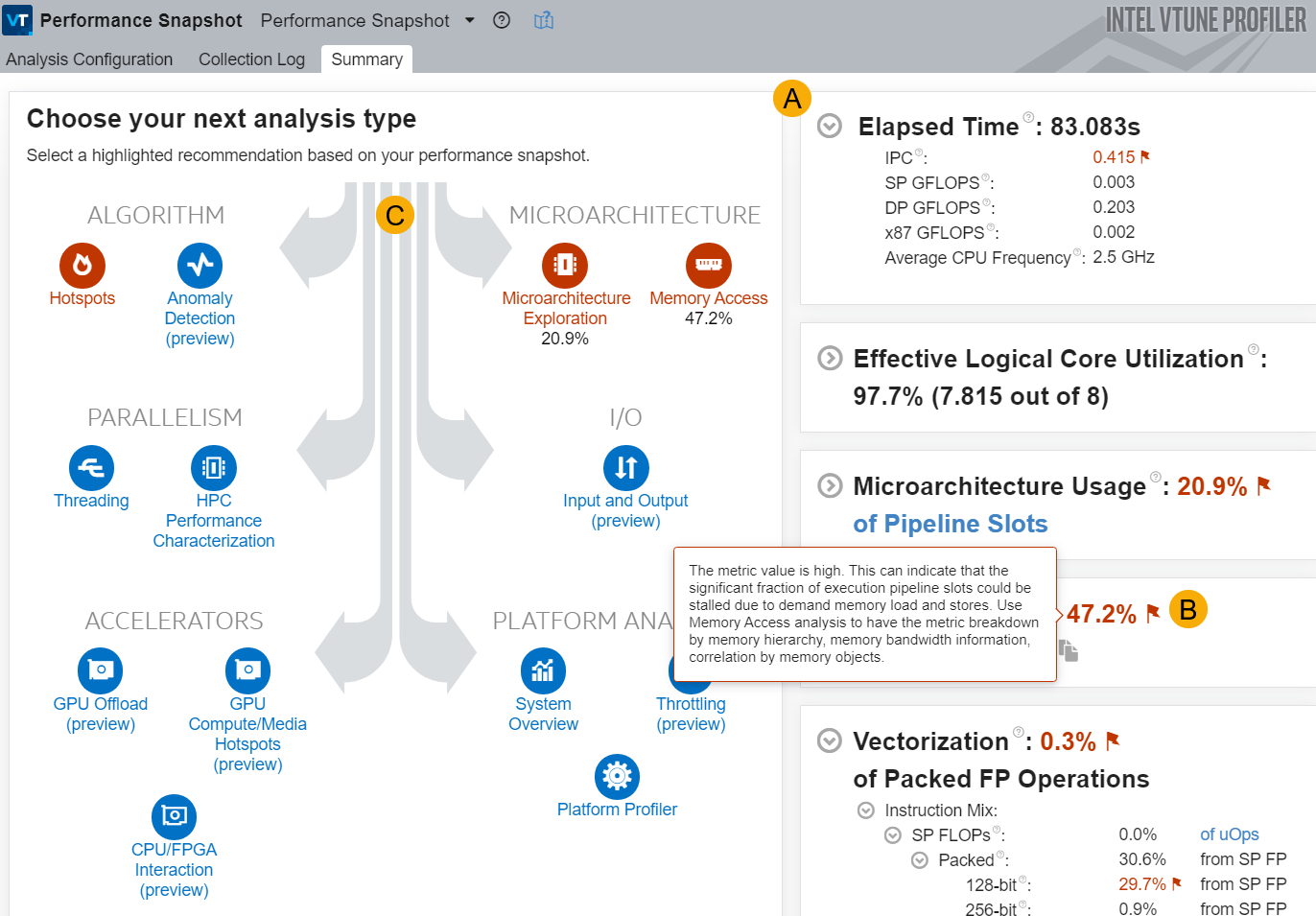
- performance-snapshot
生成程序的性能快照,如下所示
- hotspot
hotspot分析是我们最常用的功能。hotspot提供了火焰图窗口,可快速定位到程序中的热点函数或循环。它的功能丰富,提供了自顶向下和自底向上的分析窗口,用户可根据线程、用户空间、内核空间、是否包含内联函数、是否包含循环,对火焰图中的调用栈进行筛选。
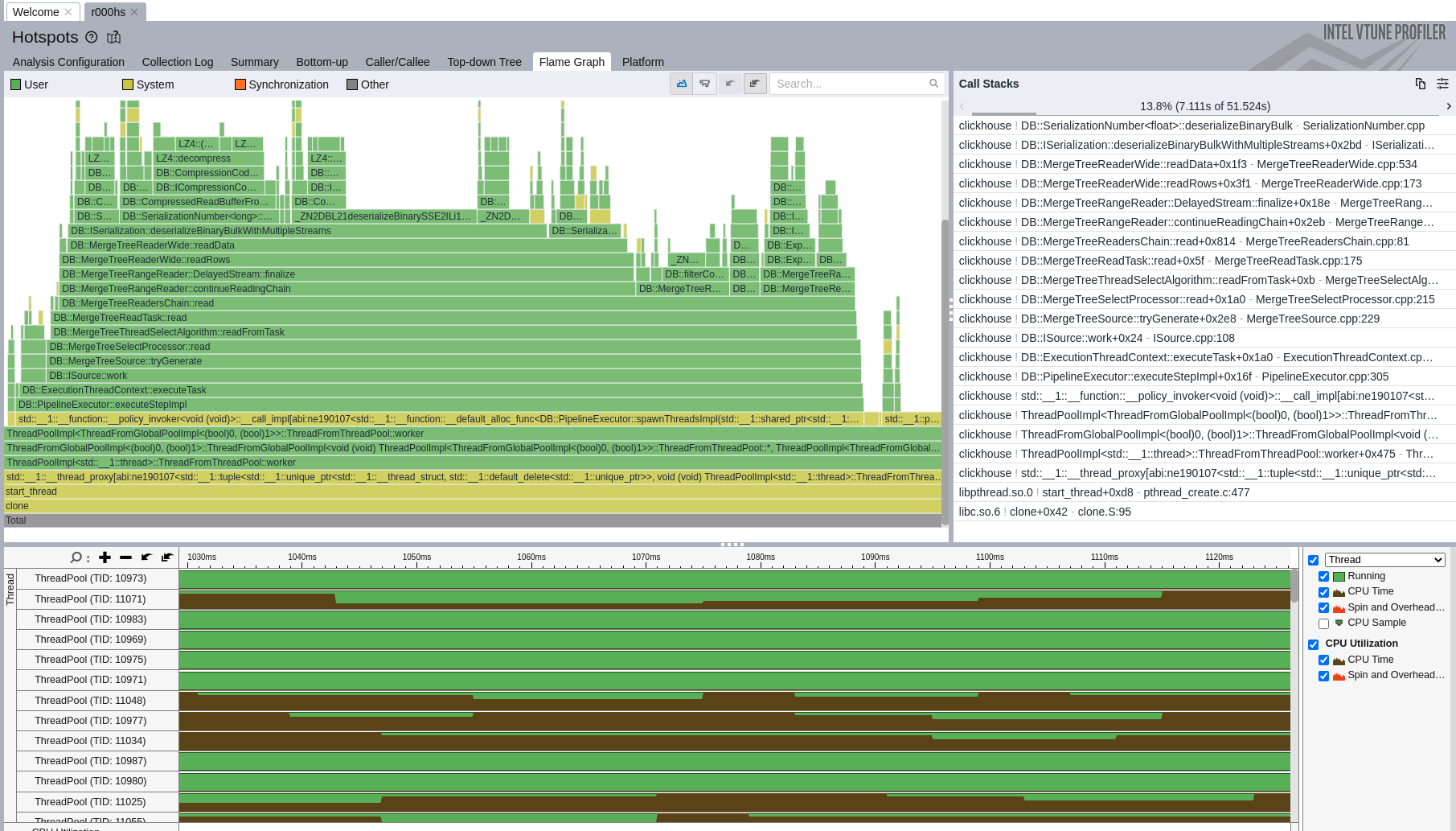
另外它还提供了根据选中symbol查看源代码和汇编代码的功能,通过汇编代码分析,我们可快速确定关键路径上某些优化是否生效,如函数内联、自动向量化、循环展开等。这为我们进一步的CPU调优提供了具体的指导。
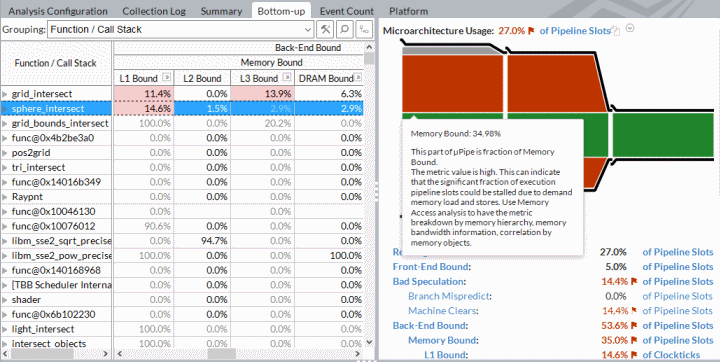
- uarch-exploration
微架构探索分析基于自上而下的微架构分析方法(Top-Down Microarchitecture Analysis),通过分层组织的事件指标,帮助开发者快速定位应用程序在CPU执行过程中的主要性能瓶颈。该方法将CPU流水线的瓶颈分为四大类:- Retired Bound:表示CPU周期被有效指令消耗,说明大部分指令都被顺利执行和退休。Retiring比例高通常意味着程序已较为高效,进一步优化空间有限。
- Front-End Bound:前端瓶颈,指CPU取指和解码阶段受限,可能由于指令缓存未命中、分支预测失败、解码带宽不足等原因导致。前端瓶颈高时,需关注代码布局、指令本地性和分支优化。
- Bad Speculation:错误推测,指由于分支预测失败、回滚等导致的无效执行。Bad Speculation比例高时,优化方向包括减少分支复杂度、提升分支预测准确率等。
- Back-End Bound:后端瓶颈,指指令已进入执行阶段但因资源受限(如内存带宽、端口冲突、缓存未命中等)而阻塞。Back-End Bound高时,需关注内存访问模式、数据结构优化和并发资源竞争等问题。
通过Intel Vtune的微架构探索分析,可以直观地看到各类瓶颈的占比,结合详细的热点函数和调用栈信息,有针对性地优化程序性能。例如,若Front-End Bound占比高,可考虑优化代码布局和减少分支;若Back-End Bound占比高,则应关注内存访问和数据局部性。
Intel Vtune常用命令:
- 首先确保程序正在运行中,通过
vtune -collect <type> -target-pid=<pid>采集数据。其中pid是待观测的进程id,type表示不同的子功能。hotspots采样生成火焰图,并进行代码级热点分析,uarch-exploration对应Microarchitecture Exploration, 分析CPU流水线的瓶颈。performance-snapshot用于生成性能快照。 - 然后运行
vtune-gui打开GUI界面,在其中导入上一步生成的数据目录,即可进行下一步分析和改进。
compiler explorer
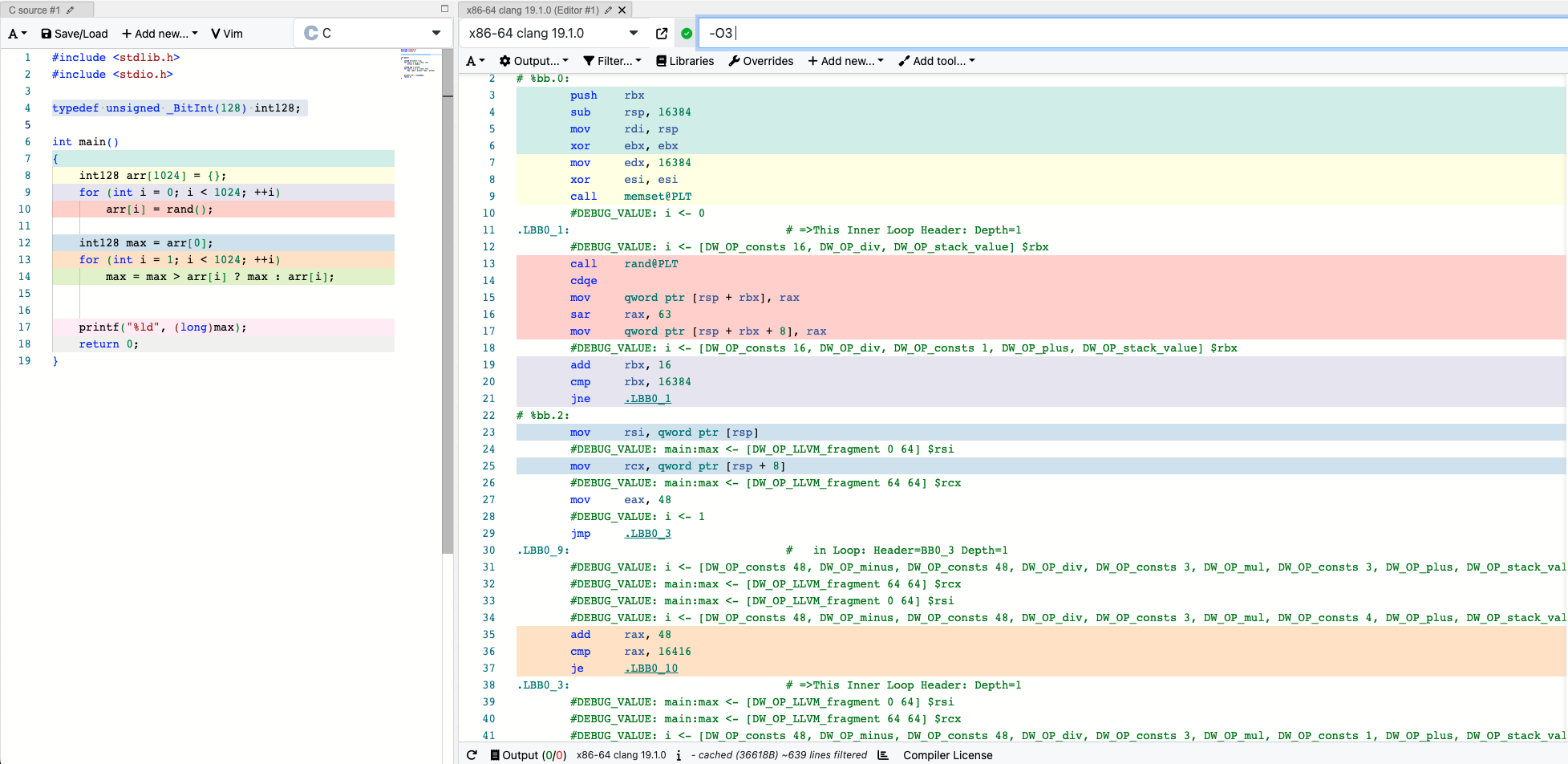
compiler explorer 是一个流行的在线编译器探索工具,支持多种主流编程语言(如 C/C++、Rust、Go 等)和多种编译器(如 GCC、Clang、MSVC)。它允许用户在网页端实时编写代码,并查看编译器生成的汇编代码、反汇编结果以及编译器优化效果。
在性能优化和底层调优过程中,compiler explorer 具有以下典型用途:
- 汇编分析:可以直观地看到不同代码实现、不同编译选项(如
-O2、-O3、-march=native等)下生成的汇编代码,便于分析编译器是否做了如函数内联、循环展开、自动向量化等优化。 - 快速验证优化点:在尝试微优化(如算法变体、内存访问模式调整)时,可即时验证优化是否生效,避免“想当然”。
例如,在分析某个关键路径函数时,可以将其核心实现粘贴到 compiler explorer,结合不同编译参数,观察编译器是否自动向量化、是否消除了冗余指令等,从而为进一步的性能调优提供依据。
CPU调优工具总结
| 工具/方案 | 适用场景/特点 | 典型用途/优势 | 缺点 |
|---|---|---|---|
| clickhouse-flamegraph | 开源项目,可视化CH查询的CPU消耗,基于system.trace_log | 直观展示各query的热点函数,适合分析CH内部算子性能瓶颈 | 采样频率高时对性能有影响,依赖CH日志,可能不适用于所有场景 |
| Linux perf | 通用、低开销,支持多种事件采样(CPU、cache、分支等) | 火焰图、热点分析、指令级分析(perf stat/top/record/report/annotate),适合C++/Native程序调优 | 输出信息较为底层,分析门槛高,对新手不友好 |
| Intel Vtune | x86平台强大分析工具,支持GUI和命令行 | 火焰图、热点分析、源代码分析、指令级分析、微架构瓶颈(Retiring/Front-End/Back-End/Bad Speculation)等多维度分析 | 商业软件,对硬件平台有要求 |
| compiler explorer | 在线汇编分析工具,支持多种编译器和优化选项 | 验证编译器优化(如向量化、内联),对比不同代码实现的底层指令生成, 适合快速验证 | 仅分析单个函数/代码片段,无法反映真实运行时性能,无法采样实际热点 |
内存调优工具
我们都知道,不管是Vanilla Spark还是Gluten, 在生产环境中executor进程限定了最大使用内存。这意味着不管是jvm还是Native Engine都运行在内存受限的环境中。在Gluten灰度上线过程中,内存OOM是一个常见的性能问题。这就要求我们使用一些内存调优工具定位出进程的内存瓶颈在何处。
tcmalloc
tcmalloc(Thread-Caching Malloc)是 Google 开源的一款高性能内存分配器,广泛应用于高并发、高性能的服务器程序。与标准的 malloc 相比,tcmalloc 通过为每个线程维护独立的内存缓存,减少了线程间的锁竞争,大幅提升了多线程环境下的内存分配和释放效率。
tcmalloc提供了heap profiler,可对Native Engine中的内存申请和释放进行采样,还可从采样数据生成可视化的火焰图。Gluten + CH使用tcmalloc进行内存调优可参考:https://github.com/apache/incubator-gluten/blob/main/docs/developers/UsingGperftoolsInCH.md
注意: CH编译时默认使用jemalloc作为其内存池实现,因此在使用tcmalloc进行性能调优之前,需要重新编译CH和Gluten, 禁用JEMALLOC: -DENABLE_JEMALLOC=0
jemalloc
jemalloc 是一个高性能的通用内存分配器,广泛应用于数据库、Web 服务器等对内存分配效率要求较高的系统(如 ClickHouse、Redis、Facebook 等)。与传统的 glibc malloc 相比,jemalloc 在多线程环境下表现更优,能够有效减少内存碎片和锁竞争,提高分配与释放的吞吐量。
jemalloc 支持丰富的内存分析与调优功能,包括内置的统计信息、内存分布追踪和可视化工具。通过环境变量(如 MALLOC_CONF)可以灵活配置其行为,便于开发者定位内存泄漏、分析内存使用模式和优化内存分配策略。在 ClickHouse 和 Gluten 等系统中,jemalloc 通常作为默认的内存分配器,保障高并发场景下的稳定性和性能。
Gluten + CH中使用jemalloc进行内存调优可参考:https://github.com/apache/incubator-gluten/blob/main/docs/developers/UsingJemallocWithCH.md
Linux Vtune
Linux Vtune除了CPU调优之外,还可用于内存调优。它提供了两个子功能
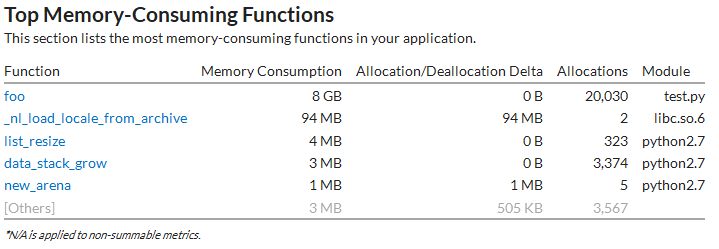
- memory-consumption
用于统计程序在一段时间内的内存消耗. 如下所示,窗口中显示了内存消耗排名靠前的函数列表及内存分配/释放大小。实际上,通过该功能不仅能得到当前系统的内存瓶颈,还可找到可能的内存泄露。
- memory-access
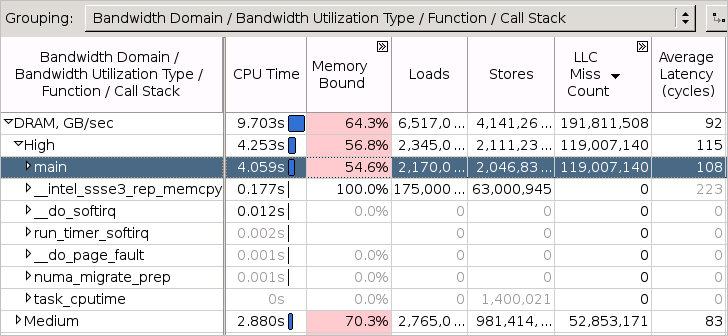
用于定位访存相关的性能问题。如下所示,窗口中显示了每个函数的cpu time、loads、stores、Memory-Bound(访问L1, L2, L3, DRAM)占CPU流水的百分比。
address sanitizer
随着C++代码复杂性的增加,内存管理和指针操作变得更加难以追踪,内存越界、悬挂指针、未初始化内存读取等问题也更容易出现。AddressSanitizer(ASan)是一款由LLVM和GCC支持的内存错误检测工具,能够在运行时检测出常见的内存访问错误,包括堆/栈溢出、Use-After-Free、内存泄漏等。CH本身在编译中已经继承了ASAN, 用户可通过-DSANITIZE=address在编译时开启ASAN。
在使用ASAN联编译Gluten + CH Backend之后,在运行之前修改启动代码
export LD_PRELOAD="/usr/lib/llvm-18/lib/clang/18/lib/linux/libclang_rt.asan-x86_64.so:/usr/local/clickhouse/lib/libch.so" # driver启动前加载asan共享库
export ASAN_OPTIONS="halt_on_error=false" # driver探测到内存错误时不要退出
./sbin/start-thriftserver.sh
xxxxx # 其他配置项
--conf spark.executorEnv.LD_PRELOAD="/usr/lib/llvm-18/lib/clang/18/lib/linux/libclang_rt.asan-x86_64.so:./libch.so" # executor启动前加载asan共享库
--conf spark.executorEnv.ASAN_OPTIONS="halt_on_error=false" # executor探测到内存错误时不要退出
内存调优工具总结
| 工具/方案 | 适用场景/特点 | 典型用途/优势 | 缺点/注意事项 |
|---|---|---|---|
| tcmalloc | 高性能内存分配器,支持heap profiler采样与火焰图 | 采样内存分配/释放热点,定位内存泄漏、碎片等问题 | CH默认用jemalloc,需重新编译禁用jemalloc |
| jemalloc | CH默认的高性能内存分配器,支持丰富的内存统计和调优 | 内存分布追踪、泄漏分析、优化分配策略,适合高并发场景 | 启动前需配置环境变量,需手动生成火焰图,分析门槛较高 |
| Linux Vtune | 支持memory-consumption和memory-access分析 | 统计内存消耗、定位分配热点、分析访存瓶颈,支持可视化 | 商业软件,对硬件有要求 |
| AddressSanitizer | 编译期插桩,运行时检测内存越界、Use-After-Free等错误 | 快速发现内存访问错误、泄漏,适合开发调试阶段 | 有一定性能开销,需重新编译,线上环境慎用 |
这些工具可结合使用,帮助开发者在Gluten+CH Backend等复杂系统中定位和解决内存相关的性能瓶颈与稳定性问题。
Gluten相关工具
Gluten自身也提供了工具,用于定位Spark ETL任务中的性能瓶颈。
Spark Web UI
Spark Web UI 是 Spark 提供的可视化监控和诊断工具。Gluten会在任务执行过程中收集每个task的每个算子中native算子的性能指标,Gluten会将这些指标汇总,最终集成到Spark Web UI中。
因此查询有没有offload到Gluten中执行,我们都能够从Spark Web UI中查看任务的性能指标,包括:
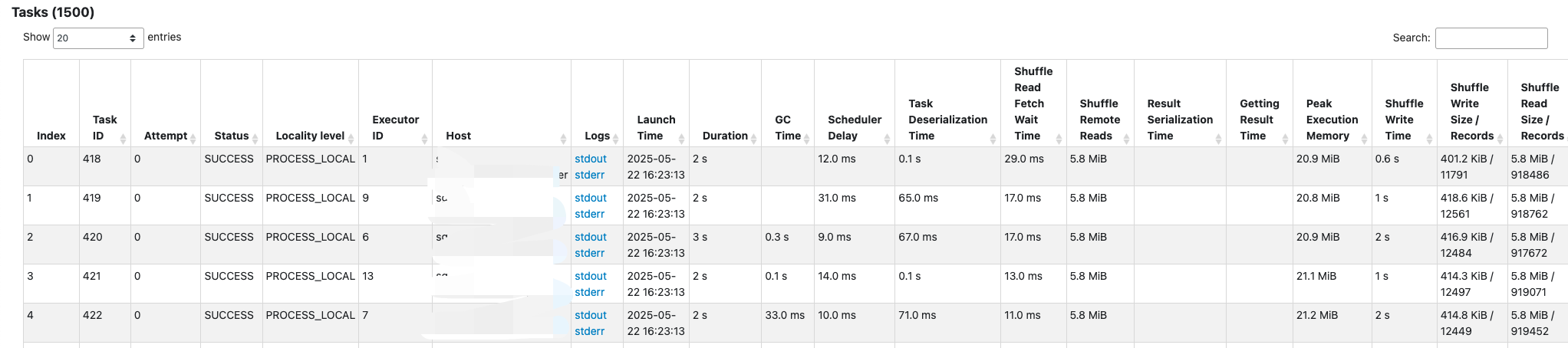
- Stages & Tasks:展示每个Stage或Task的执行时间、输入/输出数据量、Shuffle读写数据量等。可定位瓶颈在哪个Stage,Stage中Task是否发生数据倾斜。

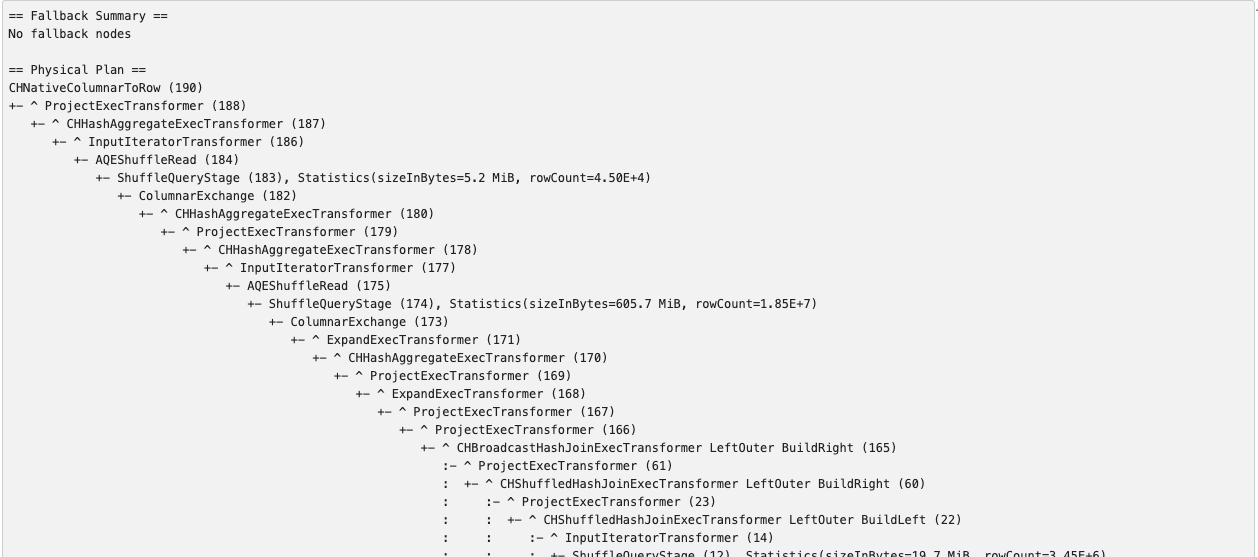
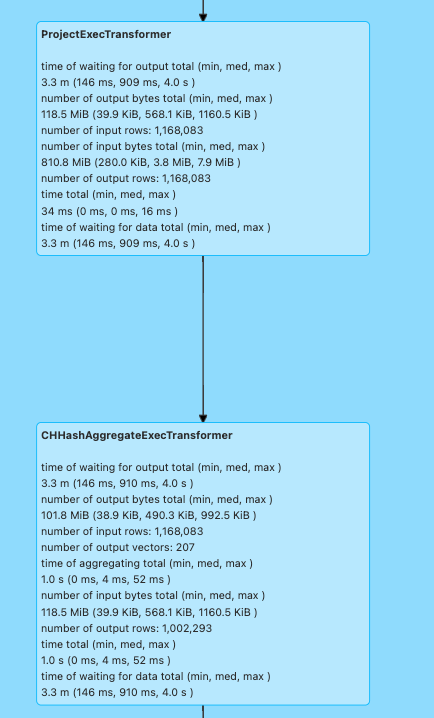
- Gluten SQL:展示每条SQL中的物理执行计划、算子Fallback汇总,还包含每个算子的执行时间、等待时间、输入输出数据量等细分指标,适合分析复杂查询的执行流程。
- Executors:展示各Executor的CPU、内存、磁盘、Shuffle等资源使用情况,便于发现资源瓶颈、内存溢出等问题。
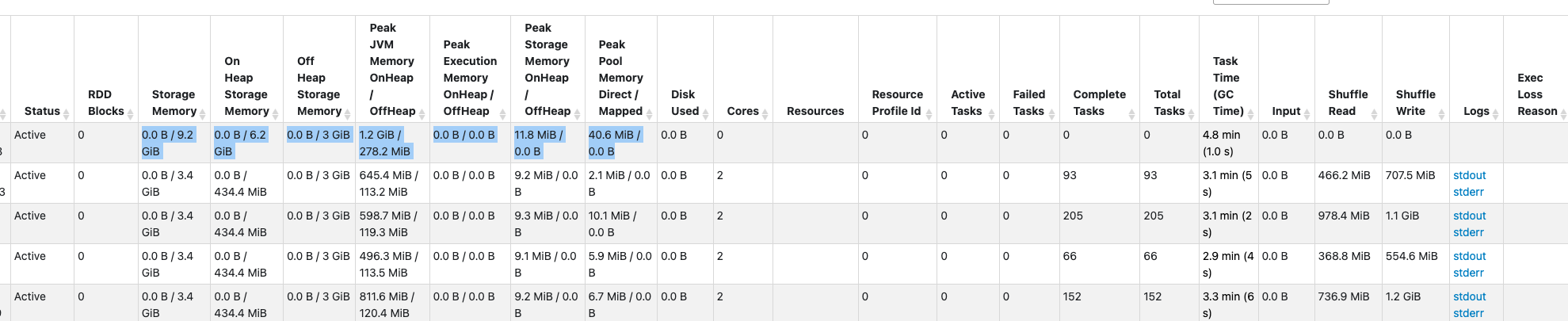
通过 Spark Web UI,可以直观地观察到 Gluten + CH Backend可以在SQL/Stage/Operator这几个层级下查看资源消耗和性能表现,方便定位和分析Spark离线ETL任务的性能瓶颈。
Spark日志
Spark日志(Driver/Executor日志)是排查 Gluten + CH Backend 运行异常、性能问题的重要依据。Spark日志中包含以下有用信息:
- CH物理计划:通过分析每个task所执行的物理计划,可深入了解 native engine 实际执行的算子和表达式。例如,Scan ORC/Parquet文件时读取了哪些列,执行Project算子时执行了哪些表达式,是否开启了JIT优化,这些信息都包含在Task的CH物理计划中。关于CH物理计划的解读请参考Gluten中Substrait算子的转化和CH算子的实现
- CH pipeline统计信息:通过 Spark 配置项
--conf spark.gluten.sql.columnar.backend.ch.runtime_config.dump_pipeline=true,可日志中输出task执行的CH pipeline的详细统计信息,包括pipeline中个算子的执行耗时、等待耗时、输入输出数据量等。将日志中的dot脚本转化为svg,如下所示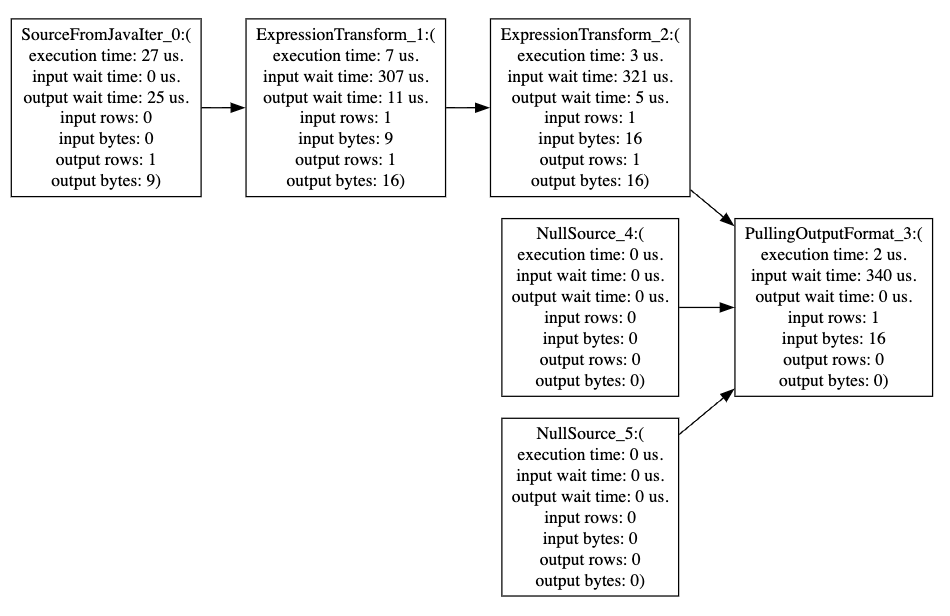
- Performance Counter: 每个task完成时都会在spark log中输出性能指标,如下所示
---------------------Task Performance Counters(2)-----------------------------
SelectedRows |1 | (Number of rows SELECTed from all tables.)
SelectedBytes |9 | (Number of bytes (uncompressed; for columns as they stored in memory) SELECTed from all tables.)
ContextLock |7 | (Number of times the lock of Context was acquired or tried to acquire. This is global lock.)
RealTimeMicroseconds |12979 | (Total (wall clock) time spent in processing (queries and other tasks) threads (note that this is a sum).)
UserTimeMicroseconds |8000 | (Total time spent in processing (queries and other tasks) threads executing CPU instructions in user mode. This includes time CPU pipeline was stalled due to main memory access, cache misses, branch mispredictions, hyper-threading, etc.)
SystemTimeMicroseconds |8000 | (Total time spent in processing (queries and other tasks) threads executing CPU instructions in OS kernel mode. This is time spent in syscalls, excluding waiting time during blocking syscalls.)
SoftPageFaults |724 | (The number of soft page faults in query execution threads. Soft page fault usually means a miss in the memory allocator cache, which requires a new memory mapping from the OS and subsequent allocation of a page of physical memory.)
OSCPUVirtualTimeMicroseconds |14372 | (CPU time spent seen by OS. Does not include involuntary waits due to virtualization.)
LogDebug |16 | (Number of log messages with level Debug)
LogInfo |5 | (Number of log messages with level Info)
LoggerElapsedNanoseconds |267993 | (Cumulative time spend in logging)
ConcurrencyControlSlotsGranted |1 | (Number of CPU slot granted according to guarantee of 1 thread per query and for queries with setting 'use_concurrency_control' = 0)
ConcurrencyControlSlotsAcquired |1 | (Total number of CPU slot acquired)
简而言之,Spark日志提供了分析具体Task性能表现的详细数据。通过这些数据,开发者可以了解Task具体执行了哪些计算,每个算子消耗了多少资源,方便开发者深入native engine底层去发现性能瓶颈,进行针对性的优化。
总结
本章系统梳理了在 Gluten + ClickHouse Backend 性能优化过程中常用的工具链,涵盖了基准测试、CPU 调优、内存分析以及 Gluten 相关的监控手段。通过合理选择和组合这些工具,开发者能够高效定位性能瓶颈,量化优化效果,并持续提升系统的稳定性与执行效率。无论是底层代码的微调,还是大规模 ETL 任务的全局分析,合适的工具都是性能优化不可或缺的利器。
参考
文章作者 后端侠
上次更新 2025-05-26