Gluten+CH backend介绍
文章目录
Gluten介绍
随着存储技术的进步,特别是SSD和万兆网卡的普及,IO性能得到了显著提升,此时CPU计算逐渐成为至于大数据处理速度的新瓶颈。而基于jvm的语言对CPU向量化的支持要远远小于其他native语言(c++/rust)。目前开源社区中比较成熟的开源Native Engine有
- Velox, Meta开源,以库的形式提供OLAP系统的核心功能:计划、表达式、向量化执行等
- CH, Yandex开源,生态强大,使用者众多。
- 其他:DuckDB等。
Databricks的Photon项目开启了使用Native Engine技术加速Spark查询的先河。在这样的背景下,Gluten项目于2021年由Intel和Kyligence共同发起,旨在将spark的可扩展性、优化器、容错能力和native engine的向量化执行能力结合起来,来加速spark查询。在各个大厂普遍降本增效的背景下,该项目获得了越来越多的关注,也得到了社区的广泛支持,先后有BIGO、美团、阿里云、网易、百度、微软等知名企业加入到Gluten的开发和贡献中来。2024年3月份gluten加入到apache孵化器。在这个赛道上,Gluten还有其他竞争者,如快手的Blaze和苹果的Apache Datafusion Comet,不过从功能完善度和社区活跃度上看,Gluten处于领先地位。
Gluten架构设计
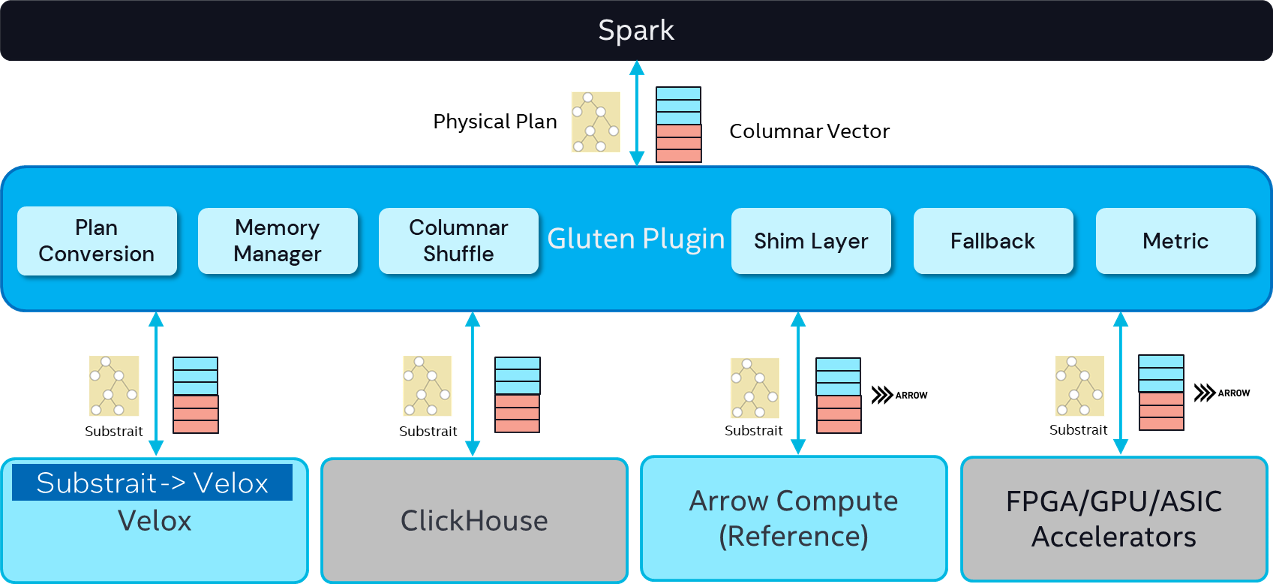
以上是Gluten的整体架构设计。Spark提供了插件机制,插件可以在不侵入Spark自身代码的前提下重写Spark plan, 从而实现定制化的功能。Gluten就是以插件的形式集成到Spark中。
在Physical Plan交给Gluten Plugin 的时候,会添加一些扩展的规则,然后把 Physical Plan 转换成语言无关的 Substrait Plan。经过这个转换后再交由下面的各种Native向量化引擎去执行计算。各自的向量化引擎会根据SubstraitPlan构建自己的Execute pipeline,然后读取Input数据去做计算,计算完后都会以列式方式返回给Spark。
在整个流转过程当中,Gluten的Plugin层起到承上启下的关系。Gluten Plugin有哪些组件呢?
- Plan Conversion: gluten插件拿到spark的物理计划之后,plan conversion会通过扩展spark rule将其转化为substrait plan, substrait plan再通过jni接口传递给底层的native engine. native engine拿到substrait plan之后,首先会将其转化成自身的plan, 然后基于自身plan构建pipeline, 最后执行pipeline返回列式结果。列式结果再通过jni接口返回到jvm。
- Memory Manager: 虽然native engine和jvm是不同语言,但是他们在同一个进程之内,共享相同的内存空间,native engine属于offHeap内存,jvm属于onHeap内存。为了避免spark driver/executor进程超出限制,也为了能充分利用分配的内存上线,对native engine和jvm中内存的统一管理就显得尤其重要。
- Columnar Shuffle: Shuffle是spark任务执行过程中比较重的算子,join/aggregate/sort算子都会触发shuffle。spark自带shuffle reader的输出是行式的,为了能给native engine提供列式输入,必然要在shuffle算子后置一个行转列(R2C)算子,同样的为了兼容native engine的列式输出,shuffle writer也需要前置一个列转行(C2R)算子。但是不管行转列还是列转行都没有任何实质计算,只是为了兼容native engine执行。为了消除行转列开销,gluten扩展出了Columnar shuffle。
- Shim Layer: 我们知道Spark的版本一直在升级,不同版本的内部实现会有一些微小差异。Gluten通过Shim Layer来兼容这些diff。截止目前Shim Layer兼容的spark版本有3.3, 3.4, 3.5。
- Fallback: spark中有很多算子和表达式,gluten在发展初期不可能完全支持他们。当遇到gluten不支持的情况,首先会通过fallback机制退回到jvm执行。类似上面的shuffle, 由于jvm是行式执行,native engine是列式执行,一旦算子出现fallback, 在二者的边界必然要引入r2c, c2r开销,造成额外的性能开销,甚至性能不如全部在jvm中执行。因此Fallback其实是为了保证功能正确的无奈之举。为了避免Fallback对性能造成太大影响,仅支持对包含leaf节点的计划树进行fallback,整个计划中fallback次数有上限。
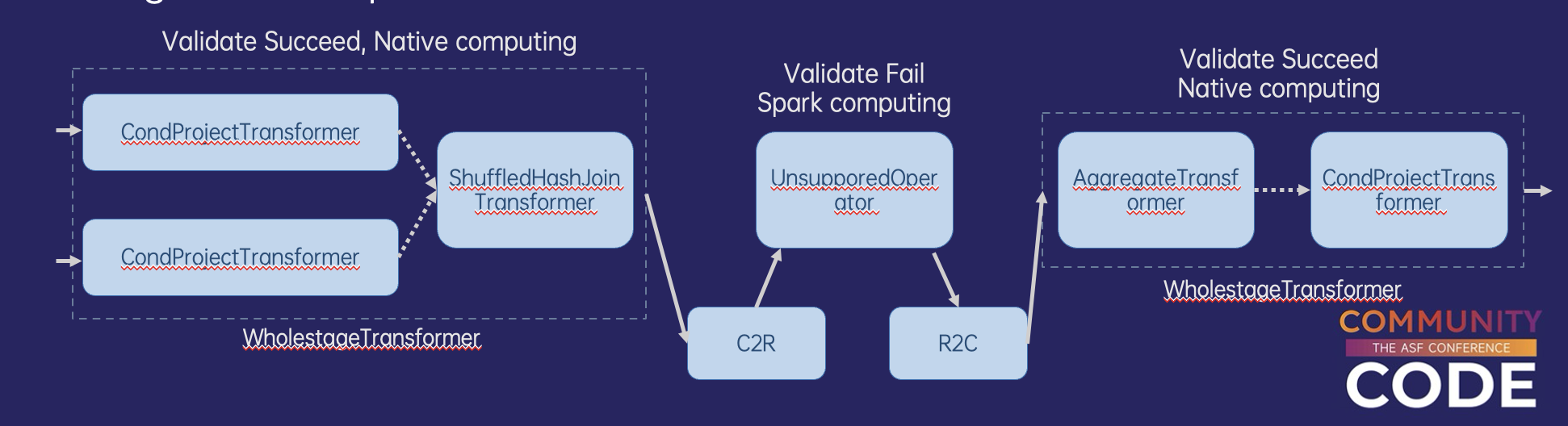
- Metrics:收集native engine执行过程中的指标,上报给spark, 方便在webui中可视化。一般包含input rows, input bytes, output rows, output bytes, execution time, waiting time for input, waiting time for output.
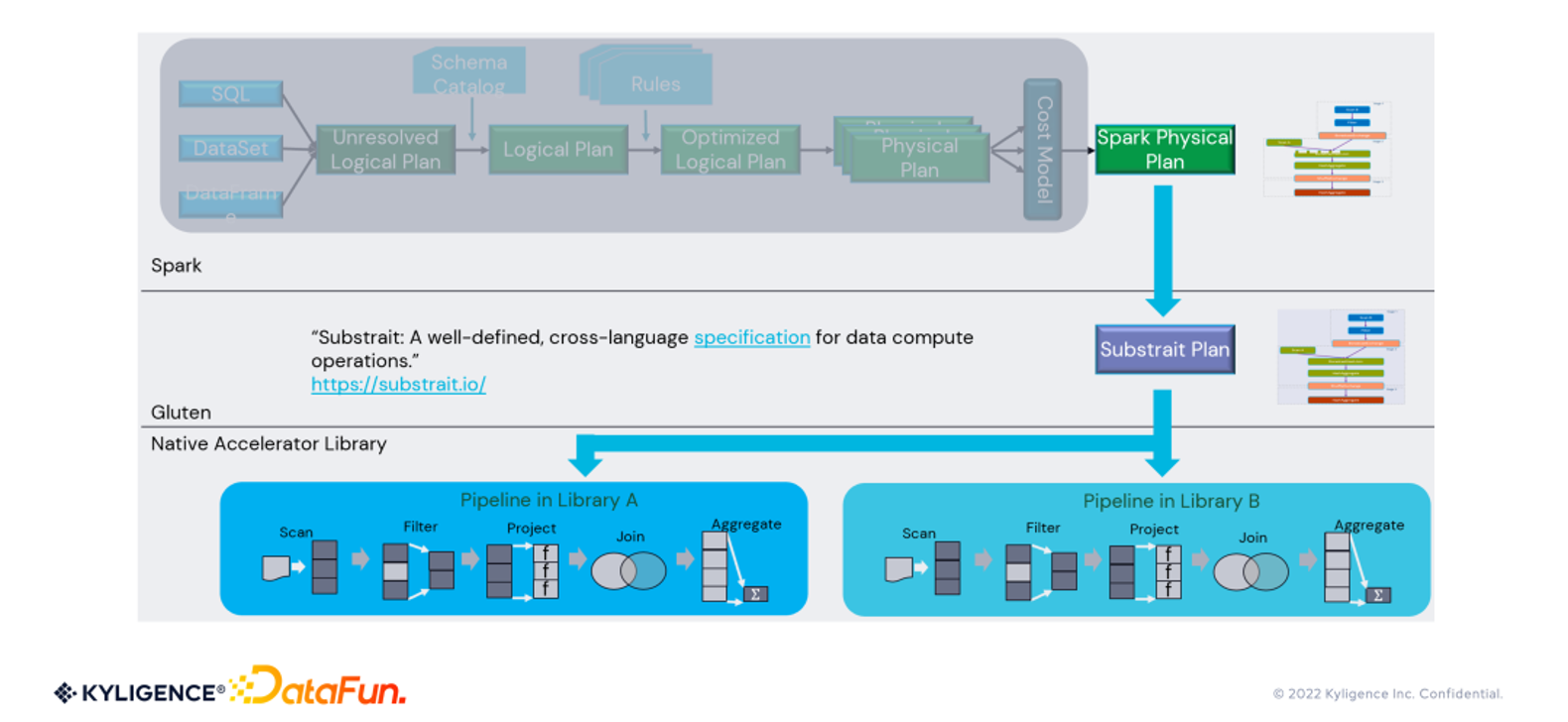 以上是gluten计划的详细转换过程,我们看到:
以上是gluten计划的详细转换过程,我们看到:
- spark层面:用户可能以不同的方式表示计算逻辑: spark-sql, dataset, 或dataframe, spark对这些逻辑统一处理,首先生成unresolved plan, 绑定catalog中元数据之后,生成logical plan。不管来自spark还是gluten,都会有一系列的rule对logical plan进行改写,生成optimized logical plan, 最终生成physical plan。
- gluten层面:gluten通过注入rule,改写spark physical plan, 将其转化成对应的substrait plan。Substrait是一个开源项目, 旨在通过一个统一的计划表示层,在不同的查询引擎之间进行数据交换。
- native engine层面: 拿到substrait plan之后,先转化为自身的physical plan, 然后构建pipeline,最后执行。
我们的工作
我们的目标是使用Apache Gluten加速生产环境离线ETL任务。
Gluten目前支持两种Native Engine, Velox与ClickHouse。我们最终选择了ClickHouse作为计划执行的后端。理由有三
- 社区与生态:ClickHouse社区比较开放, 只要是有利于性能的改动,社区都比较欢迎,PR响应的也很及时。而且CH经过这么多年的发展,它的算子、表达式、类型等核心功能都支持的比较完善。
- 团队技术栈:我们团队维护有CH集群,对CH有丰富的使用和二开经验。在加入Gluten社区之前,我们也给CH社区贡献了一些比较大的PR, 包括hive engine, mergetree启动加速,parallel hash join等。
- 工具链:CH的开发工具链非常完善,有利于保证代码质量,包括compiler/profiler/sanitizer/tests/benchmarks/performance report等。
在我们加入Gluten + CH Backend的开发之前,它的功能支持还处于初级阶段,很多类型、算子、表达式都不支持。经历了两年多的开发,我们持了生产环境所有的算子、类型和表达式,保证了所有spark任务都能够通过Gluten offload到CH backend中执行。目前Gluten已基本在我们生产环境落地,相比Vanilla Spark能够节约一半的资源。
类型支持
我们支持了以下类型,覆盖了生产环境的所有类型。
- Null
- Timestamp
- Short
- Byte
- Binary
- Decimal
- Array
- Map
- Struct
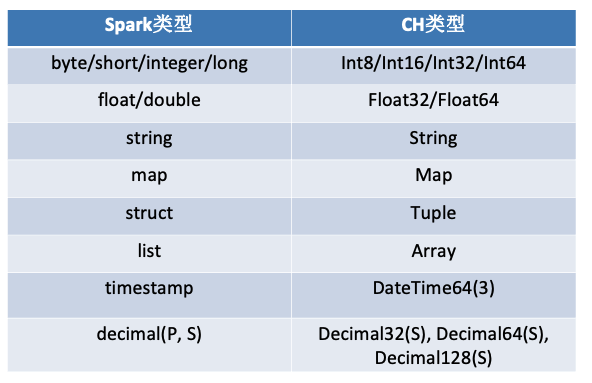
归功于CH社区的完备,所有Spark类型在CH中都有对标,spark和CH中类型的映射关系如下。
函数支持
函数分为三类,简单函数、聚合函数和窗口函数。我们支持100+简单函数、10+聚合函数和窗口函数,覆盖了生产环境的所有函数。
函数支持的开发上,分为三种情况
- CH中已有对标函数,且语义相同。这种情况只需在spark和ch表达式之间建议简单映射即可。
- CH中已有对标函数,语义在某些corner case下不同。这种情况需要将spark function转化为ch 表达式组合。例如CH中
substring(‘hello’, offset = 0)返回的是空字符串,而Spark中substring(‘hello’, offset = 0)返回的是hello, 为了消除他们之间的diff, 我们将spark函数substring(str, start)转化为substring(str, if(start = 0, 1, start))。我们引入了Function Parser框架,用户可基于其扩展某个spark函数转成CH表达式的定制化逻辑,避免了重新开发新CH函数。 - CH无对标函数。这时候就需要在CH中实现新函数。在这个过程中,我们尽量将通用功能贡献给CH社区。
算子支持
我们实现了以下算子,覆盖生产环境中所有算子
Scan/Generate/Filter/Union/Sort/Limit算子
Scan算子: CH本身支持了对HDFS数据源的读取,也支持ORC/Parquet/JSON/Text等格式,因此只需通过Gluten集成。注意这里需考虑partition column的特殊处理。 Filter/Union/Sort/Limit等算子:CH中都有实现,需在gluten将其与spark一一映射。这里不赘述
Generate算子:对应spark sql中lateral view explode/posexplode, CH中有对应实现Array Join算子。
Expand算子
对应spark sql中的with cube,with rollup或grouping sets语句。我们基于CH实现了Expand算子。我们实现了两版Expand算子。
第一版Expand算子会在Aggregate算子之前,将一行数据按照grouping sets扩展成多行数据,从而实现expand语义。
expand -> aggregate partial -> shuffle -> aggregate final
第二版AdvancedExpand算子基于第一版做了优化,将aggregate放在aggregate partial阶段之后。这样做的好处是,将expand后置,能够减少aggregate partial处理的数据量。
aggregate partial -> advanced expand -> shuffle -> aggregate final
Aggregate算子
CH中aggregate分为两阶段,第一阶段对输入数据进行部分聚合,第二阶段对第一阶段产生的中间结果进行进一步聚合。但是在高基数场景下容易导致第二阶段OOM,我们针对第二阶段支持了spill功能,使其在内存紧张时能够自动将hash table spill到本地磁盘。
Join算子
CH中join算子有不同的实现,其中merge join有partial merge join和full merge join, hash join有grace hash join, hash join, parallel hash join. 不同join算法的实现可参考ClickHouse Joins Under the Hood - Hash Join, Parallel Hash Join, Grace Hash Join。我们在gluten中实现了自适应的join算法选择,同时补足了grace hash join的right/full join语义,和ASOF JOIN语义。
行列转换算子
实现Spark Row行式数据和CH Block列式数据的互换。如下所示,设计上将所有类型分为两类,定长类型(integer/decimal/floating), 和变长类型(array/map/struct/string)。定长类型的行列转换由FixedLengthDataWriter和FixedLengthDataReader实现,变长类型的行列转换由VariableLengthDataReader和VariableLengthDataWriter实现。详细设计
总结
通过引入Gluten并结合ClickHouse作为Native Engine,我们成功实现了Spark离线ETL任务的加速,显著提升了资源利用率和执行效率。在类型、函数和算子支持方面,我们实现了与生产环境高度兼容的能力,确保了所有Spark任务能够顺利迁移并稳定运行在Gluten+CH架构下。
文章作者 后端侠
上次更新 2025-05-22