《Everything You Always Wanted to Know About Compiled and Vectorized Queries But Were Afraid to Ask》笔记
文章目录
1 引言
大部分现代查询引擎使用向量化和代码生成其中一种。
使用向量化的系统: VectorWise,DB2 BLU, columnar SQL Server, Quickstep 使用代码生成的系统:Hyper, Apache Spark, Peloton
为了公平的比较向量化和代码生成在OLAP场景中孰快孰慢,论文实现了两个用于测试的系统,分别基于向量化和代码生成,前者叫Tectorwise(TW), 后者叫Typer。实验结果表明,两种方法都能带来高效的执行引擎,并且性能差异通常不会很大。基于编译的引擎在计算密集型查询中具有优势,而矢量化引擎在隐藏cache-miss延迟方面表现更好,如group by, hash join中。
2 向量化 vs. 代码生成
向量化是pull-based的,每个算子都有next方法生成元组块,元祖块中包含多个元组,这摊销了迭代器调用开销。实际查询工作是由执行简单操作的原语组成,每种具体列类型都对应特定原语实现。通过摊销和类型特化,消除了传统引擎的大部分开销。
在代码生成中,每个算子实现了基于推送的接口,为给定查询生成代码。生成的代码针对查询的数据类型进行了特化,并将所有运算符融合成一个由非阻塞算子组成的流水线(可能嵌套)循环。然后可以将此生成的代码编译成高效的机器码。
2.1 向量化算法
以向量化风格实现的函数有两个约束
- 仅工作在一个数据类型上
- 必须一次处理多个元祖 如下所示,(a)是常规风格的过滤实现,(b)是向量化风格的过滤实现。前者在一个循环中同时处理两个predicate, 后者每个predict各在一个循环中处理。这意味着如果predict数量有多个时,每个predict执行后都会出现临时的中间结果,最后对这些中间结果进行合并,得到最终的输出结果。

2.2 向量化hash join和group by
hash join实现如下,probeHash批量计算输入向量的hash值,ht.findCandidates根据hash向量批量访问hash table, 输出匹配的candidates.

group by分成两个阶段,这两个阶段都会使用包含group by keys和聚合状态的哈希表。
3 实验方法
在测试查询时,我们为向量化执行和编译执行使用相同的物理查询计划。我们不将查询解析、优化、代码生成和编译时间纳入我们的测量范围。Tectorwise 和 Typer 之间的唯一区别是查询执行方法:向量化与数据中心编译执行。
3.1 相关工作
向量化: MonetDB/X100, VectorWise… 代码生成:Hyper, Peloton, Spark
3.2 查询处理算法
论文实现了五种算子,scan, selection, project, join, aggregate。和生产级代码不同,论文实现不对算数表达式做overflow检查。scan本质上是一个for循环,用于扫描relatiion. selection被转化为if分支。投影通过将表达式转化为C代码实现。aggregate分为两阶段,有利于cache-friendly的并行化处理,第一阶段合并高频项并输出到每个分区,第二阶段聚合每个分区中的分组。
3.3 负载
从TPC-H中选择5个代表性的查询, 数据集sf=1。这五个查询涵盖了 TPC‐H 最重要的性能挑战,任何在它们上表现良好的执行引擎很可能也会在TPC-H全部查询上高效。

4 微架构分析
4.1 单线程性能
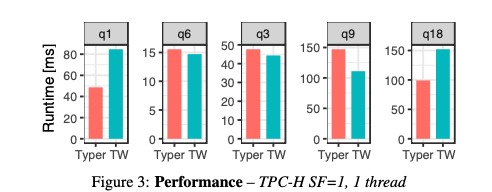
现象:对于某些查询( Q1 、 Q18 ),Typer 更快,而对于其他查询( Q3 、 Q9 ),Tectorwise 更高效。相对性能范围从 Typer 快 74% ( Q1 )到 Tectorwise 快 32% ( Q9 ) 。
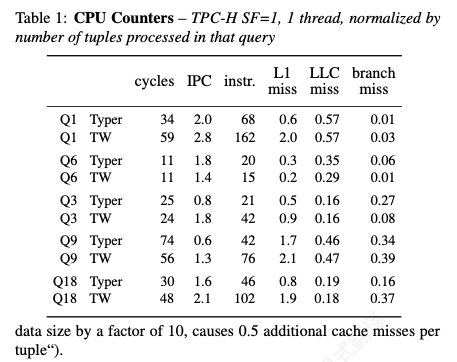
现象:Tectorwise 执行显著更多的指令(高达 2.4×)并且通常有更多的 L1 数据缓存未命中(高达 3.3×)。 解释:Tectorwise 将所有操作分解为简单步骤,并且必须在这些步 骤之间生成中间结果,这导致额外的指令和缓存访问;相比之下,Typer 通常可以将中间结果保存在 CPU 寄存器中, 因此可以用更少的指令执行相同的操作。 结论:Typer 对于可以 将中间结果保存在CPU 寄存器中且缓存未命中较少的计算查询更高效。
现象:对于 Q3 和 Q9,其性能由哈希表探测的效 率决定,Tectorwise 比 Typer 更快(分别快 4% 和 32% )。 解释:向量化在隐藏cache-miss时表现更好。Tectorwise的hash table probe只是一个简单循环,只执行probe, 因此cpu的乱序引擎可以推测的更远,并生成很多outstanding load. 而代码生成中循环更复杂,其中可能包含了scan, selection, hash table probe, aggregate的逻辑,cpu乱序窗口会更快被复杂循环填满,导致其发出的load相比向量化更少。此外复杂循环中branch-miss的代价更大。
综上,通过微架构分析,论文发现 向量化和代码生成性能相当, Typer在计算密集型且cache-miss较少时更高效 TW在隐藏cache-miss上做的更好。
4.2 解释和指令缓存
基于volcano风格的系统对每个处理的元组块执行昂贵的虚函数调用和类型分发。这就是向量化执行的解释开销,因为它不会对实际查询工作有贡献。DBMS中解释部分在1.5% (sf=10)。 那么向量化为什么比代码生成有更多指令呢?问题不在与向量化的解释开销(毕竟只占1.5%),而在于将原始结果物化到向量中的load/store指令。
4.3 向量大小
batch size < 64 or >64K时,性能显著下降。这是因为小向量不足以均摊解释开销,大向量无法放入CPU cache. 通常1k的尺寸对所有查询来说是一个很好的设置。
5 数据并行执行(SIMD)
向量化引擎的基础是SIMD。AVX-512 SIMD指令集相比之前的AVX2或SSE4更强大,几乎所有操作都支持 掩码,并且增加了新指令,如压缩和扩展
4.3 向量大小
batch size < 64 or >64K时,性能显著下降。这是因为小向量不足以均摊解释开销,大向量无法放入CPU cache. 通常1k的尺寸对所有查询来说是一个很好的设置。
5 数据并行执行(SIMD)
向量化引擎的基础是SIMD。AVX-512 SIMD指令集相比之前的AVX2或SSE4更强大,几乎所有操作都支持 掩码,并且增加了新指令,如压缩和扩展
5.1 数据并行选择
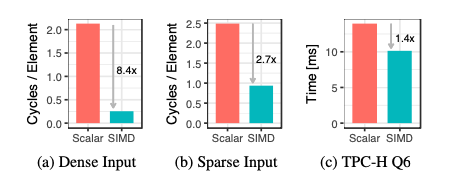
现象:在dense input下,SIMD相比Scalar实现加速8.4x, 在sparse input下,SIMD相比Scalar实现加速2.7x。而在TPC-H Q6中,SIMD的加速比只有1.4x。 解释:由于选择向量导致的稀疏数据加载和步长变化导致cache-miss增多。TPC-H Q6的SIMD实现中,内存成为瓶颈,Q6的4个predicate中,只有第一个受益于SIMD,后面三个predicate计算都是基于选择向量的。
5.2 数据并行hash table probe
有两个使用SIMD的机会,计算哈希值,哈希表查找。 计算哈希值使用murmur2实现,该环节加速2.3x. 哈希表查找使用gather和其他SIMD指令加速,该环节加速1.4x
现象:TPC-H 连接查询整体提升却没有1.4x-2.3x如此明显 解释:随着hash table的增长,SIMD受益减少,执行成本由memory latency主导。
5.4 总结
现象:基于AVX512的SIMD实现,在微基准测试中相比Scalar实现有8.4x的性能提升;但是在TPC-H查询中,性能提升小的多(如连接查询才1.1x)。 解释:因为大多数 OLAP 查询受限于数据访问, 而数据访问尚未(目前)从 SIMD 中获得太多好处,而不是 受限于计算,而计算是 SIMD 的优势
6 查询内并行化
Morsel‐driven的并行性是为 HyPer开发的,因此 可以在 Typer 中非常直接地实现。 通过共享状态和屏障,Tectorwise实现表现出与Typer 相同的工作负载平衡并行化行为。
6.2 多线程执行
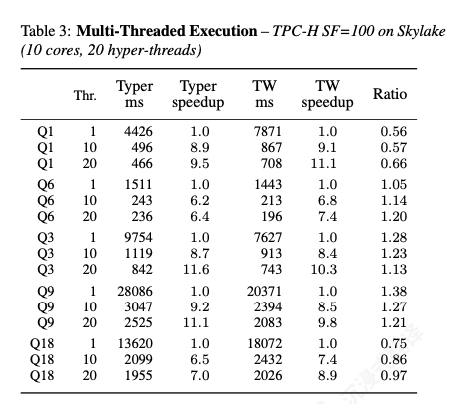
首先TW和Typer多线程下的性能有接近完美的可扩展性。其次线程数增加时,两个系统的性能差距会缩小。这表明多线程在隐藏一些微架构次优代码的缺点方面非常有效。
8 总结

计算:代码生成在计算密集型查询方面表现更好, 因为它能够将数据保留在寄存器中,从而需要执行的指令更少。 并行数据访问:向量化执行在生成并行缓存未命中方面略好一些,因此在访问用于聚合或连接的大哈希表的内存 受限查询中具有一定优势。 SIMD:最近一直是硬件架构师用 来提高 CPU 性能的主要机制之一。理论上向量化执行更有可能从中受益。实际上,我们发现收益很小,因为大多数操作都由内存访问成本主导 并行化:使用morsel-driven并行调度,向量化和代码生成的引擎都可以在多核 CPU 上很好地扩展
向量化引擎的优势:
- 无编译开销:因为所有的原语都是提前编译好的。代码生成中为了减少编译时间,可关闭某些llvm优化过程。
- 调优方便:运行时绑定到原语,而不是生成代码。代码生成中,为了方便调优,会在llvm ir之上引入抽象层,简化代码生成。
- 自适应执行:运行时根据数据特征切换原语。例如,在聚合过程中,将输入元组分区到多个选择向量中,每个分组键对应一个选择向量,当分组键较少时,可提升聚合性能。
代码生成引擎的优势
- 符合OLTP场景的需求,对fast stored procedures生成代码并编译。
- 多语言支持
文章作者 后端侠
上次更新 2025-05-20