clickhouse集群zookeeper平滑搬迁实践
文章目录
更多精彩内容,请关注微信公众号:后端技术小屋
〇、背景
注:为简化表述,本文中将clickhouse简称为ck, 将zookeeper简称为zk。
我司从去年年底开始启动从香港到新加坡机房的迁移。目前Clickhouse集群所有实例都已经搬迁从香港搬迁到了新加坡机房,还剩下其依赖的Zookeeper集群在香港机房,因此我们近期准备将Zookeeper集群平滑搬迁到香港机房。
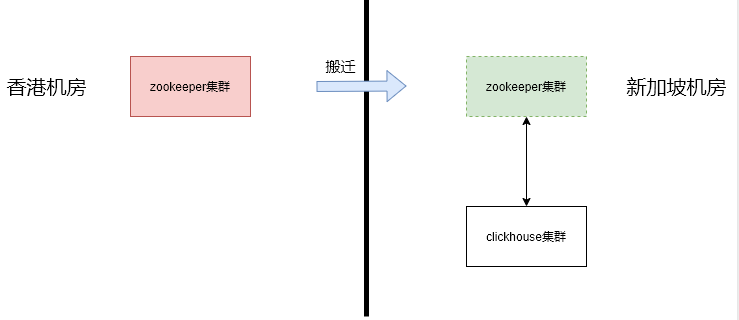
0.1 目标与挑战
0.1.1 zk跨洲搬迁需对用户基本无感知
ck集群发展到现在已经承载了整个公司的实时数据分析需求,还支持了许多在线服务。这要求ck集群不能够停机,在任何时候都是可用的。ck集群每时每刻都在执行数据插入和查询、表变更,而ck在架构设计上重度依赖zk做元数据存储、副本同步和表变更,zk一旦不可用,ck的读写都会受到影响。zk集群的迁移中间必然引起leader的切换,如何在zk集群搬迁的过程中保证读写,这是一个不小的挑战。
0.1.2 热升级+动态配置更新
为了实现上面的目标,我们在迁移的过程中,一方面要从写入层做好重试,避免zk切主过程中的失败。同时,也要尽可能的缩短zk不可用的时间。对zk的操作都要采用热升级的方式,滚动操作,同时因为zk的集群ip都换了,必然要更改很多配置,所有的配置也尽量采用reload的方式,而不是重启服务。
一、整体方案
1.1 第一步:zk从静态配置版本升级到动态配置版本
zk 3.5.0之后支持动态配置特性。利用动态配置特性可方便进行扩容和缩容操作,而不需要对整个zk集群中的所有实例进行滚动重启。但是不巧的是,ck用的zk集群还没有使用动态配置,因此zk集群搬迁的第一步就是将zk集群从静态配置版本平滑升级到动态配置版本,简化后续的扩容和缩容操作。zk动态配置版本详情可参考:https://backendhouse.github.io/post/zookeeper_dynamic_config/
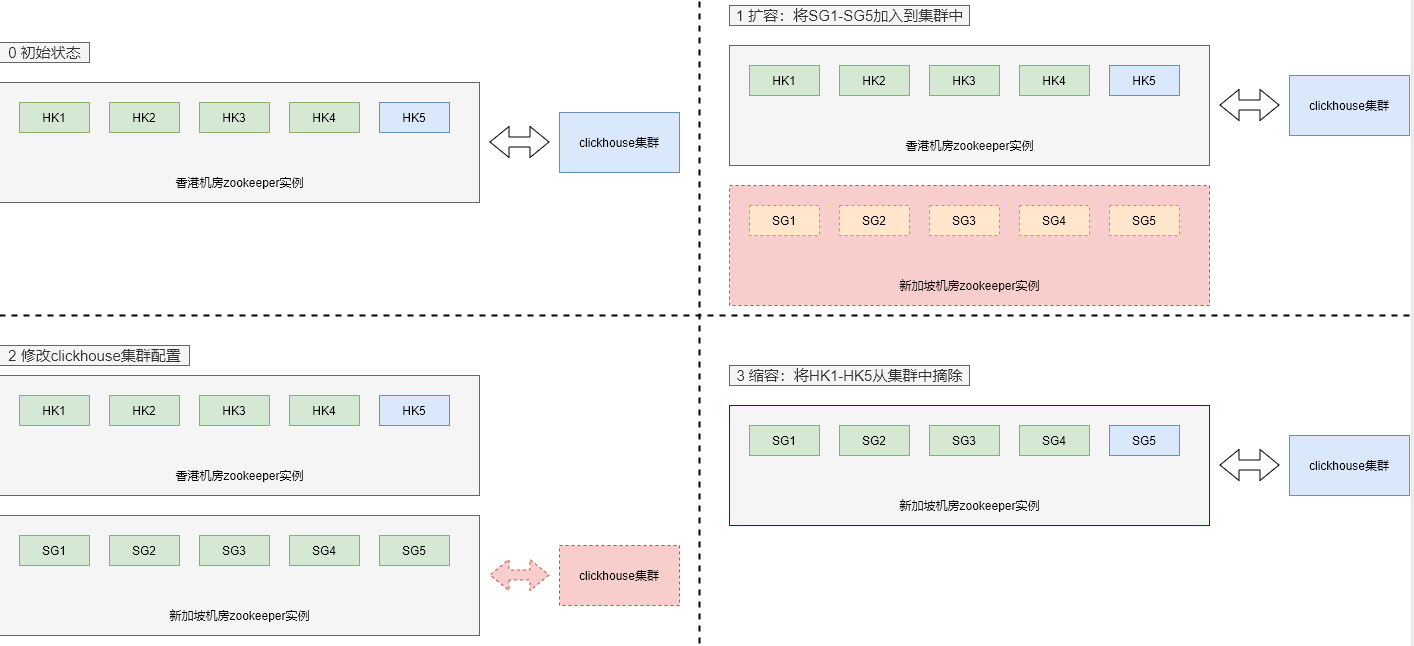
1.2 第二步:zk扩缩容实现搬迁
第二步,在ck集群升级到动态配置版本之后,通过扩容和缩容操作实现zk集群从香港老机器到新加坡新机器的平滑搬迁:
- 扩容:将新加坡机房的新机器一台一台加入到zk集群中
- ck实例修改zk配置:将zk配置全部从老机器换成新机器
- 缩容:将香港机房的老机器一台一台从zk集群中摘除。
二、遇到的问题和解决方案
为了保证线上zk搬迁过程中不出问题,我们事前进行充分的影响面预估和线下演练,在这个过程中发现了以下问题:
2.1 zk静态配置版本与动态配置版本不兼容
在1.1中,首先将zk中的Follower实例从静态配置升级到动态配置版本时,发现升级中的Follower实例报错:
Follower报错日志如下:
2021-02-25 11:07:03,081 [myid:5] - WARN [QuorumPeer[myid=5](plain=/0:0:0:0:0:0:0:0:2185)(secure=disabled):Follower@96] - Exception when following the leader
java.io.EOFException
at java.io.DataInputStream.readInt(DataInputStream.java:392)
at org.apache.jute.BinaryInputArchive.readInt(BinaryInputArchive.java:63)
at org.apache.zookeeper.server.quorum.QuorumPacket.deserialize(QuorumPacket.java:85)
at org.apache.jute.BinaryInputArchive.readRecord(BinaryInputArchive.java:99)
at org.apache.zookeeper.server.quorum.Learner.readPacket(Learner.java:158)
at org.apache.zookeeper.server.quorum.Learner.registerWithLeader(Learner.java:336)
at org.apache.zookeeper.server.quorum.Follower.followLeader(Follower.java:78)
at org.apache.zookeeper.server.quorum.QuorumPeer.run(QuorumPeer.java:1271)
2021-02-25 11:07:03,081 [myid:5] - INFO [QuorumPeer[myid=5](plain=/0:0:0:0:0:0:0:0:2185)(secure=disabled):Follower@201] - shutdown called
java.lang.Exception: shutdown Follower
at org.apache.zookeeper.server.quorum.Follower.shutdown(Follower.java:201)
at org.apache.zookeeper.server.quorum.QuorumPeer.run(QuorumPeer.java:1275)
同时,尚未升级的Leader实例报错如下:
2021-02-26 19:35:08,065 [myid:6] - WARN [LearnerHandler-/xx.xx.xx.xx:52906:LearnerHandler@644] - ******* GOODBYE /xx.xx.xx.xx:52906 ********
2021-02-26 19:35:08,066 [myid:6] - INFO [WorkerReceiver[myid=6]:FastLeaderElection$Messenger$WorkerReceiver@285] - 6 Received version: b00000000 my version: 0
2021-02-26 19:35:08,066 [myid:6] - INFO [WorkerReceiver[myid=6]:FastLeaderElection@679] - Notification: 2 (message format version), 5 (n.leader), 0xb0000000c (n.zxid), 0x2 (n.round), LOOKING (n.state), 5 (n.sid), 0xb (n.peerEPoch), LEADING (my state)b00000000 (n.config version)
2021-02-26 19:35:08,067 [myid:6] - ERROR [LearnerHandler-/xx.xx.xx.xx:52908:LearnerHandler@629] - Unexpected exception causing shutdown while sock still open
java.io.IOException: Follower is ahead of the leader (has a later activated configuration)
at org.apache.zookeeper.server.quorum.LearnerHandler.run(LearnerHandler.java:398)
经过定位,发现问题出在静态版本的Leader实例与动态版本的Follower实例不可共存。在串行升级zk的过程中,为了尽量减少zk集群不可用时间,我们先升级完所有Follower, 最后再升级Leader。 当一个Follower实例从静态配置版本升级到动态配置版本之后,此时Leader还处于静态配置版本,其config version是0; 而Follower此时处于动态版本,config version大于0。
Follower启动之后会请求Leader,请求数据中带上config version. Leader收到请求之后会对Follower的config version做校验,如果发现对方config version大于自己,便抛异常(Follower is ahead of the leader)并主动关闭连接。
if (learnerInfoData.length >= 20) {
long configVersion = bbsid.getLong();
if (configVersion > leader.self.getQuorumVerifier().getVersion()) {
throw new IOException("Follower is ahead of the leader (has a later activated configuration)");
}
}
而Follower读到EOF之后也会抛异常(EOFException),并不断重试。
摆在眼前的解决方案有两种:
- 方案一:串行升级改成并行升级,避免静态版本与动态版本的实例同时存在。
- 方案二:由于静态版本和动态版本同时存在的时间很短,zk增加一个临时版本,该版本中去掉Leader对Follower的config version检查,绕过上述问题
考虑到zk集群中数据较多,zk实例启动时间较长,并行升级会导致zk集群在2-4min内不可用。一旦出现问题发生回滚,zk集群不可用时间还会翻倍,风险较大。于是我们摒弃方案一,选择方案二:先将静态版本串行升级到去掉config version检查的静态版本,再升级到动态版本。
2.2 ck无法动态加载zk配置
在线下演练过程中发现,在1.2中,当修改clickhouse配置文件中的zk server列表后,配置变更并不会被ck动态加载。而clickhouse上的应用已经如此之多,其中不乏一些2B业务或对实时性要求非常强的业务,通过重启ck集群去加载新的zk server列表显然不可接受。
最终的解决方案是增加clickhouse对zk配置动态加载的支持,从而避免重启ck集群影响用户。目前这一优化已经合并到社区,PR: https://github.com/ClickHouse/ClickHouse/pull/14678
2.3 zk实例重启导致少量ck查询失败
ck查询一般不涉及zk交互,因此zk搬迁大部分情况下不影响ck查询。但是在线下演练过程中发现,当clickhouse开启了开关optimize_trivial_count_query之后, 对应PR: https://github.com/ClickHouse/ClickHouse/pull/7510,执行一些简单的select count查询会被zk搬迁所影响。
追查代码发现,optimize_trivial_count_query开启后,对于简单的select count查询,ck会跳过常规的查询过程,转而从metadata中获取总行数(在此过程中会访问zk),以此来提高select count的查询速度。因此,在zk集群搬迁之前,我们将clickhouse集群中的开关optimize_trivial_count_query设置为0,待zk搬迁完成之后再将其开启。
2.4 zk实例重启导致写入ck失败
在向ck写入数据时,ck依赖zk集群分配blockid,并将数据从当前副本同步到配偶副本。因此zk搬迁过程中必定会影响ck写入。而我们要做的便是将影响写入的时间段尽量缩短;同时一旦发现写入失败针对同一个分片下的副本不断重试,保证zk集群恢复时,ck写入也能自动恢复。
目前有Flink、Spark和clickhouse_sinker三个入口往ck写数据,在zk搬迁之前我们需要提前确保它们写ck的过程已经有了重试机制。
2.5 zk实例重启导致ck表变更失败
表变更操作包括创建/删除表、新增/删除/修改字段。ck集群在执行表变更时必然会访问ck集群,因此zk搬迁过程中会影响ck集群中的表变更。因为ck表变更相对于ck写入与查询来说频率较低。因此在zk搬迁过程中,我们对ck平台进行功能降级,即此时不支持ck表变更操作,以此避免zk实例重启导致ck表变更失败。
三、最终的搬迁方案
3.0 初始状态
假设香港机器:A1, A2, A3, A4, A5,新加坡机器:B1, B2, B3, B4, B5
初始状态下,zk集群部署于香港机房,初始版本为静态配置版本。
我们的目标是将zk集群搬迁到新机房,最终版本为动态配置版本。
3.1 升级到动态配置版本
版本升级路线:静态版本 -> (不带config version检查的)静态版本 -> 动态版本
3.1.1 静态版本 -> 不带(config version检查的)静态版本
串行升级,先升级Follower, 最后升级Leader。每升级完一台机器,检查集群中Leader/Follower状态,检查ck查询和写入是否有异常。等待zk实例完成启动后,接着再升级下一个zk实例。
预期影响:
- 升级Follower实例时,ck到该zk实例上的连接被断开,部分ck写入可能会报
zookeeper session expired错误,ck重连其他zk实例后恢复正常,恢复时间不超过40s。 - 升级Leader实例时,zk会进入选举周期并会产生新的Leader, ck写入会报
table in readonly mode错误,新Leader产生之后ck写入恢复正常,恢复时间不超过3min.
回滚方案:直接并行回滚到初始的静态版本
3.1.2 不带(config version检查的)静态版本 -> 动态版本
升级步骤、预期影响面、回滚方案同3.1.1
3.2 动态扩缩容
3.2.1 扩容:将新加坡新机器加入到zk集群中
串行扩容步骤:
- 在新机器B1上部署zk实例, 其配置中包含A1-A5和B1。通过
reconfig -add 6=B1:2888:3888;2181将B1加入到集群中。接着检查当前所有zk实例的本地配置是否已更新,检查Leader/Follower状态,检查ck读写是否有异常,确认无问题后扩容下一台机器 - 在新机器B2上部署zk实例, 其配置中包含A1-A5和B1-B2。通过
reconfig -add 7=B2:2888:3888;2181将B2加入到集群中。检查步骤同上 - …
- 重复执行以上步骤,直到所有新机器都已经加入到zk集群中。
预期影响:无
回滚步骤:在串行扩容过程中,如果有任何一步出现异常,则将新实例通过reconfig -remove <id>命令从集群中摘掉。
3.2.2 修改ck配置:将zk配置改成新加坡新机器
修改ck配置,将zookeeper-servers从旧机器A1-A5改成新机器B1-B5,并下发到所有ck实例。netstat命令检查ck是否与新zk实例建立连接。
<zookeeper-servers>
<node index="0">
<host>A1</host>
<port>2181</port>
</node>
<node index="1">
<host>A2</host>
<port>2181</port>
</node>
<node index="2">
<host>A3</host>
<port>2181</port>
</node>
<node index="3">
<host>A4</host>
<port>2181</port>
</node>
<node index="4">
<host>A5</host>
<port>2181</port>
</node>
</zookeeper-servers>
预期影响:无
回滚:一旦检查过程中发现异常,将ck配置回滚并重新下发。
3.2.3 缩容:将香港老机器从zk集群中摘掉
串行缩容过程中,应当遵循先缩容Follower实例,最后缩容Leader实例的顺序,具体步骤如下:
- 缩容A1: 通过
reconfig -remove 1=A1:2888:3888;2181命令,将老机器A1从集群中摘除。接着检查当前所有zk实例的本地配置是否自动更新,检查Leader/Follower状态,检查ck读写是否出现异常。确认无问题后,将老机器A1上的zk实例下线。 - 缩容A2, 操作同上
- …
- 重复执行以上操作,直到所有香港老机器都已经从zk集群中摘除。
预期影响:同3.1.1
回滚:在串行缩容过程中,如果有任何一步出现异常,通过reconfig -add <id>=<ip>:2888:3888;2181命令将待下线实例重新加入zk集群中。
四、总结
通过线下环境中充分的zk搬迁演练,我们得以及时发现zk搬迁中出现的各种问题,并一一加以解决。最终在ck用户基本无感知的情况下,完成了zk集群从香港到新加坡的平滑迁移。
更多精彩内容,请扫码关注微信公众号:后端技术小屋。如果觉得文章对你有帮助的话,请多多分享、转发、在看。

文章作者 后端侠
上次更新 2021-03-17