《An Empirical Evaluation of Columnar Storage Formats》笔记
文章目录
摘要
列式存储如Parquet ORC都是2010年左右的产物。但是这些年硬件和wordload都发生了变化。本文对Parquet ORC进行了深入分析,并对其进行了基准测试。确定了在现代硬件和现实世界数据分布中更具优势的设计原则,以知道未来格式更好适应现代技术趋势。
介绍
背景
- Parquet和ORC提出于2010年代初,用于Spark, Impala, Presto, Hive, 应对每天PB级数据增长下的数据分析需求。
- 硬件变化:磁盘性能提升了N个数量级,达到GB/s
- 数据湖兴起:高带宽,高延迟
- 学界出现了许多新的轻量级压缩方案,索引和过滤技术
目的:深入比较Parquet和ORC两种格式,包括内部原理,性能,压缩率,为下一代列式存储格式指明方向。
结论:
- Parquet和ORC之间并没有明显的优胜者,Parquet在file size上有略微的优势,因为它更激进的字典编码。Parquet在decoding性能上也更具优势,这归功于更简单的整数编码算法。而ORC在行裁剪上更具优势,因为它包含了更细粒度的zone maps.
- 大部分现实世界中的列都具有低基数的特点。因此,压缩字典代码的效率对于文件大小和解码速度至关重要。
- 更快、更便宜的存储设备意味着必须使用更快的解码方案来降低计算成本,而不是追求更激进的压缩以节省 I/O 带宽。格式不应默认使用块压缩,因为节省下来的IO带宽不一定胜过解压缩的开销。
- Parquet和ORC提供了对索引(zone map)的简单支持。随着瓶颈从io-bound转移到cpu-bound, 可将更复杂的索引结构加入到列式存储格式中,用空间换时间。
- 现有的列式格式在ML workload上效率低下。
背景和相关工作
列式存储最初由C-store, MonetDB和VectorWise提出,受益于列式压缩,向量化处理和延迟物化,性能得到大大提升。后续Meta提出了ORC格式,Twitter和Cloudera提出了Parquet格式,它们都借鉴了早期的列式存储研究。
其他列式存储格式:
- 华为CarbonData: 性能差,社区不活跃,跳过
- Arrow: 内存格式,跳过
- 最近的lakehouse:Delta Lake, Iceberg, Hudi,本质上是基于file format的table format,跳过
- Meta: DWRF是ORC的变种,提供了更好的读取和加密支持;Alpha改善ML workload下的性能。
特性分类
首先统一术语

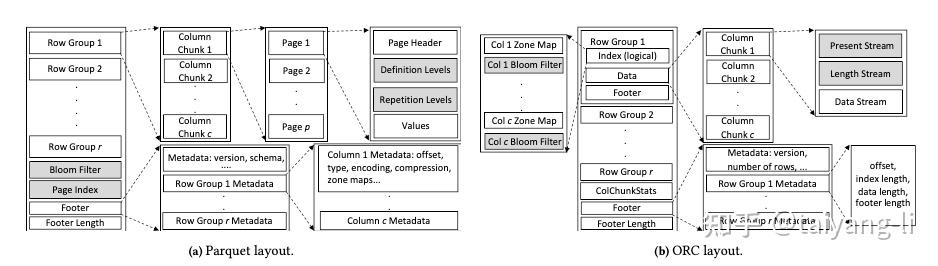
内部布局:都采用了PAX格式,首先将表水平分区成rowgroup, 再将rowgroup以列为单位进行拆分,形成列块,支持向量化查询。每个列块内的值使用轻量级编码,然后使用块压缩算法减小列块大小。Parquet和ORC的区别:
- Parquet的rowgroup使用基于行数的行组大小(1M行),而ORC使用固定的物理存储大小(64MB)。
- Parquet将其压缩单元映射到最小zone map, 而ORC压缩单元和最小zone map并不一一对应。
编码:二者都用了dict, rle, bitpacking技术。区别
- Parquet默认情况下对每个列进行dict encoding,而ORC只对字符串列使用。
- Parquet的dict encoding阈值是绝对大小,而ORC是基于比率的。
- Parquet使用dict encoding之后,对dict index进一步使用了bitpacking和rle的混合算法进行压缩, 如果相同值出现>=8次,则使用RLE, 否则使用bitpacking。而ORC使用四种方案来encode dict index或整数列。ORC方案的复杂性使得ORC压缩率更高,但是decode性能更差
压缩:二者都启动了块压缩。Parquet用户可自行选择压缩算法和级别。而ORC提供了更粗略的选项:优化速度和优化压缩。
类型系统:Parquet中有原始类型,其他类型基于原始类型构建;ORC中每个类型都有独立实现。二者都支持struct/list/map类型
索引和过滤器:Parquet和ORC在文件和行组级别都包含zone map。区别
- Parquet中最小zone map对应一个page,而ORC中对应一个固定行数。
- Parquet早期版本,最小zonemap位于page header中,这种设计会引入大量随机IO。在Parquet 2.9.0中,添加了optional PageIndex来解决该问题。ORC的最小zone map位于每个rowgroup开头。
- bloom filter: 都是可选的。ORC中bloom filter和最小zonemap具有相同粒度,彼此相邻。而Parquet中bloom filter仅在rowgroup级别创建。
注意:zone map仅在值聚集(基本排序)时才能发挥作用。
嵌套数据模型:Parquet将每个原子字段的值作为单独列存储,每个列都绑定两个相同长度的整数序列,分别是重复级别R和定义级别D, 用于嵌套结构的编码。ORC使用基于length和absense的更直观模型编码嵌套数据。Parquet的优势在于查询处理过程中读取列更少(仅原子字段),但是Parquet通常会产生更大文件大小,因为非原子字段的信息可能会在多个原子字段中重复。

压缩率分析
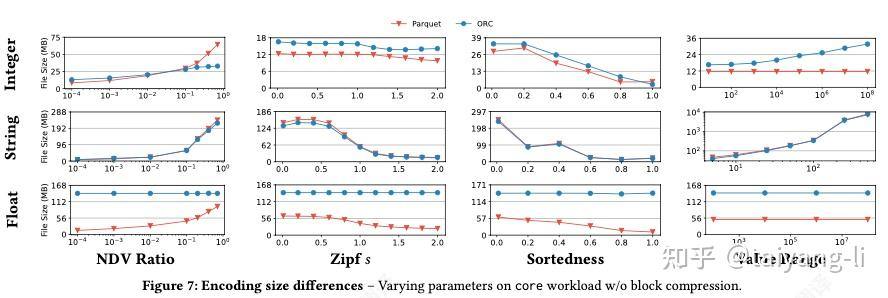
整数列
- 对于低到中等NDV比率的整数列,Parquet比ORC实现了更高的压缩率。原因:Parquet使用dict encoding之后又用了bitpacking和RLE。
- 当整数列中NDV比率继续增长时,ORC开始比Parquet压缩率更高。原因:Parquet中的dict encoding在高NDV时效率不高,而ORC复杂的整数编码算法开始起作用。
- 整数列的Zipf增大时,ORC的filesize比Parquet更早开始下降。原因:ORC更激进的RLE阈值。
- 整数列的sortedness非常大时,ORC压缩率高于Parquet。原因:ORC使用了delta encoding和FOR encoding.
- Parquet 的文件大小在整数值范围变化时保持稳定,因为其字典代码不随值范围变化. ORC 的文件大小随着值范围的增大而增大.
字符串列:对于字符串列,Parquet 和 ORC 的文件大小几乎相同,都使用字典编码
浮点数列:对于浮点数列,由于dict encoding在现实世界的浮点数上出奇地有效,Parquet 在文件大小上优于 ORC
解码速度分析
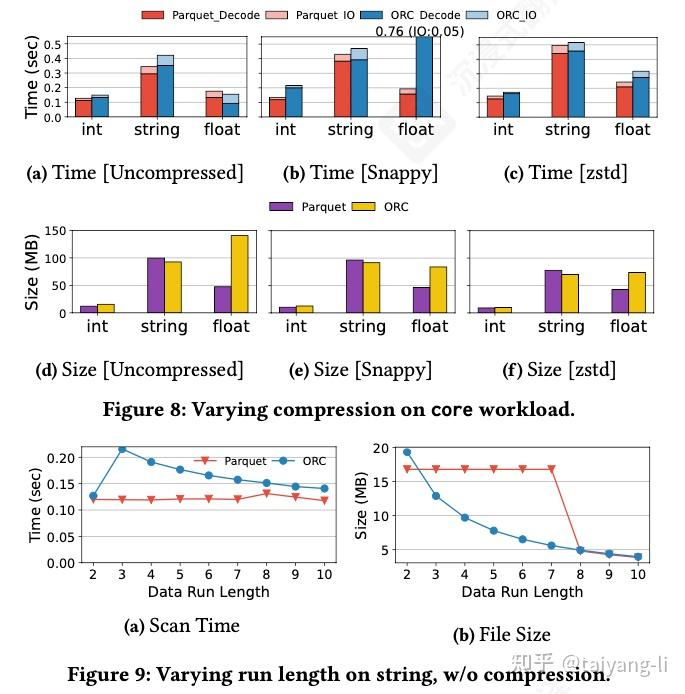
整数列
- Parquet 的整数解码速度通常比ORC。因为Parquet整数编码算法相比ORC更简单,ORC中使用了更激进(低)的RLE重复次数阈值,而RLE是没法利用SIMD的,ORC中整数编码会在四种算法中切换,增加了branch miss, 拖慢性能。
- Parquet相比ORC在string列解码速度上的优势大于整数列。因为ORC中不会对整数列进行字典编码,Parquet解码整数列时会多出来访问字典的开销。
- 对短重复序列,RLE解码相比bitpacking耗时更长。当重复次数r变大时,二者的解码性能差距变小。
浮点数列:ORC比Parquet解码性能更快,因为ORC不对float使用dict encoding。副作用是ORC filesize更大。
讨论:
- 保持encoding算法简单对于提升解码性能很关键
- 即使轻量如dict encoding也会在scan算子中增加额外的overhead, 这部分overhead可能大于因此省下来的IO time.
块压缩
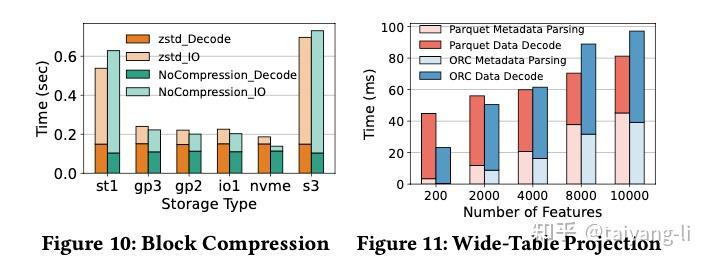
- 在所有类型上,zstd比snappy的压缩率更高。
- ORC对浮点数列的压缩率更高,因为压缩前在ORC中没有encoding。对于其他类型的列,压缩相比不压缩省下的磁盘空间有限,因为压缩前已经做了轻量级的编码。
- 对Parquet使用zstd压缩,只在慢速存储设备中有用(IO-bound)。对于更快的存储设备,特别是nvme ssd, 因为未压缩而多出来的IO time相比因为压缩而多出来的cpu time可忽略不计。
讨论: 随着存储设备越来越快,越来越便宜,由压缩带来的计算开销远大于其减少的IO开销。注意:云存储不在此列。
宽表Projection
当列数增加时,元数据的解析开销几乎线性增加,即使projection的输出列数量固定。因为Parquet和ORC中的footer structure不支持随机访问。
索引和过滤器
zone maps和bloom filters能加速低选择度的查询。然而zone maps只在列值比较集中时有效,而bloom filters只在点查中起作用。
嵌套数据模型
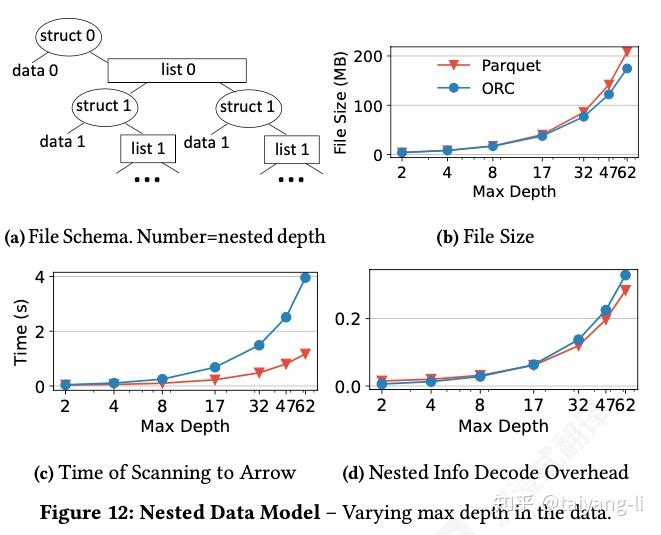
随着嵌套层数增加,Parquet filesize的增长快于ORC,ORC解码嵌套结构的耗时增长也快于Parquet.
ML workloads
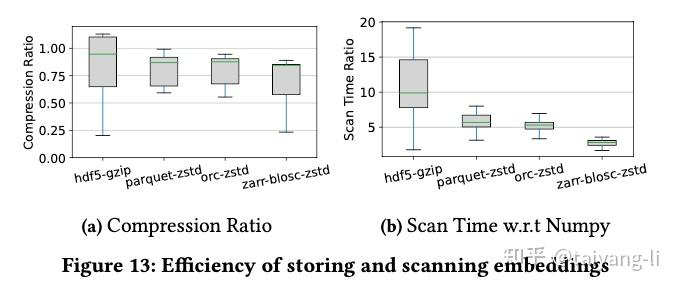
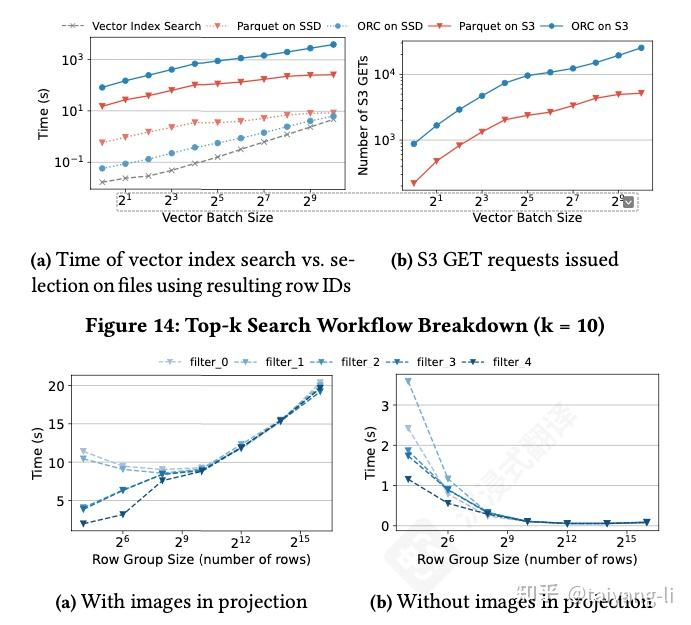
都很差,略
GPU解码
很差 略
收获和未来方向
字典编码对于大部分标量类型都有效,因为现实世界中的数据符合低基数的特征 保持简单的编码算法,有助于提升解码性能 在现代硬件中,查询变成了cpu-bound. 未来的列式存储格式应当限制使用块压缩和过重的编码算法。 未来format中元数据应当允许快速随机访问,以优化宽表查询性能。 随着存储越来越便宜,未来format中能够维护更多用于索引和过滤的结构,以加速查询 未来format应当考虑对GPU更友好的解码算法。
结论
略
文章作者 后端侠
上次更新 2025-05-20